
Spark 运行时架构
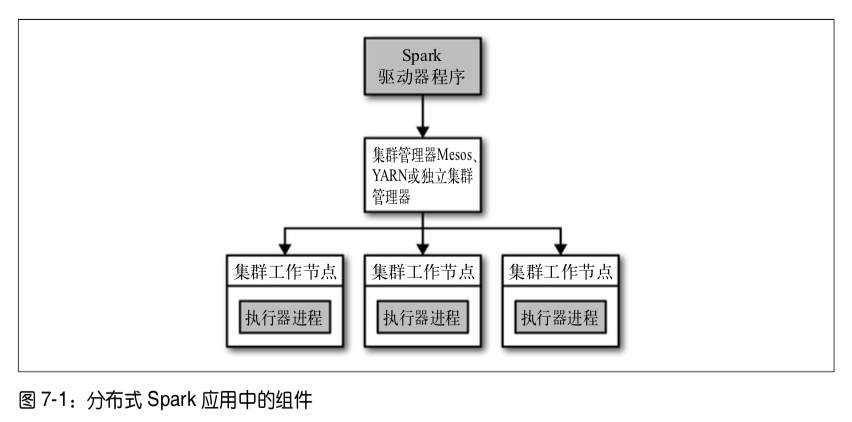
一个节点负责中央调度,即驱动器节点,其他节点称为执行器节点。驱动器节点和执行器节点一起被称为一个Spark应用
驱动器节点
驱动器是执行驱动程序中main()方法的进程,执行用户编写的代码。他的职责有以下两点:
– 把用户程序转为多个执行单元,以及将操作逻辑图转换为执行计划,并进行优化
– 为执行器调度任务。负责管理执行器节点并协调任务调度。
执行器节点
- 负责运行任务,即使失败也不会影响Spark任务的完成。
- 通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
集群管理器
在基于集群管理器部署的情况下,Spark依赖集群管理器来启动驱动器节点
应用内与应用间调度
- Spark允许工作负载设置优先级
- 通过集群管理器为不同队列定义不同优先级或容量限制
- 对于长期允许的应用,Spark提供
公平调度器来定义优先级队列
集群管理器的选择
- 从0开始,则直接选择独立集群管理器
- 如果同时需要使用其他应用,可以使用YARN或者Mesos
- Mesos提供细粒度共享选项,可将交互式应用的不同命令分配到不同CPU上,对于多用户运行交互Shell有好处
- 任何时候,最好把Spark运行在HDFS节点上
调优与调试
使用SparkConf配置Spark
在创建SparkContext时传入构造完成的SparkConf对象
val conf = new SparkConf()
conf.set("spark.app.name"."Test App")
conf.set("spark.master","local[4]")
conf.set("spark.ui.port","36000")
val sc = new SparkContext(conf)
或者在运行时使用标记设置
bin/spark-submit \
--class com.example.TestApp \
--master local[4] \
--name "TestApp" \
--conf spark.ui.port=36000 \
TestApp.jar
或者设置配置文件路径。
执行的组成部分

- 用户代码定义RDD的有向无环图
- 行动操作把有向无环图翻译为执行计划
- 任务提交集群调度并执行
步骤会以特定顺序执行,并且按照步骤之间的依赖;平级任务可能会同时执行。在每个任务内部,执行流程如下:
- 从数据存储或RDD获取输入数据
- 根据计划通过操作计算得出RDD
- 把输出写入数据混洗文件或外部存储或发回驱动器程序
关键性能考量
- 并行度
适当提高并行度以充分提高集群资源利用率- 设定参数
- 对RDD进行重新分区
repartition()
- 序列化格式
当需要进行网络传输或溢出到磁盘时,可以使用更快的序列化工具(Kryo) -
内存管理
- 调整RDD存储,数据混洗和聚合缓存区,用户代码所占内存比例
- 修改缓存策略,缓存序列化后的对象
- 资源供给
- 节点内存,核数,本地磁盘
- 给单个执行器较小的内存以提高单台机器上的执行器个数,避免过长的GC时间