
查询调度
生成调度执行器
对于每一个Stage会生成对应的SqlStageExecution实例,承载Stage启动和任务调度。

- 由
SqlQueryExecution.analyzeQuery生成subPlan - 根据subPlan信息,获得Stage执行计划
StageExecutionPlan。其中维护一个子Stage执行计划合集List<StageExecutionPlan>,其中最上层的Stage为outputStage,用于最终输出 - 由最上层的outputStage和其他参数组成SqlStageExecution。通过地柜的方式构造子Stage对象
查询调度过程
SqlStageExecution组成
- NodeScheduler 将Task分配给node的核心模块,包含以下功能
- NodeManager 获取存活的节点列表,并保存在NodeMap中,定时更新内容;缓存5s
- NodeMap 存储Presto节点信息
- IP和端口组成的节点列表
- IP组成的节点列表
- Rack组成的节点列表。仅简单的将InerAddress封装成rackId
- NodeSchedulerConfig 相关配置参数
- NodeSelector 提供各Stage中Task分配节点的算法
- NodeTaskMap 保存当前Stage分配的Task和节点映射列表
ConcurrentHashMap<Node,NodeTasks>其中NodeTasks维护一个节点对应的Task列表,并对每个Task注册监听器,确保完成后从列表中移除Task - RemoteTaskFactory 生成RemoteTask的工厂类
- StageStateMachine Stage状态监听器
NodeManager
NodeManager定义了统一获取节点的入口,保障调度task时节点可用。NodeManager定义了一下方法:
- Set getActiveNodes 获取存活的节点列表
- Set getActiveDatasourceNodes 根据catalogName获取存活节点列表(维护在Coordinator上)
- Node getCurrentNode 获取当前节点信息
- Set getCoordinators 获取协调器列表
- AllNodes getAllNodes 获取所有节点列表
- refreshNodes 刷新节点信息(每5s调用一次,如果响应异常则会被排除出Task的调度,Version也必须和协调器一致)
NodeSelector
查询调度算法的核心,提供了Stage分配Task的核心算法。
- NodeMap
维护了关于节点信息的三份列表,通过Guava的Supplier缓存。目前Rack(机架感知功能)未实现,该功能用于实现数据本地性优化 -
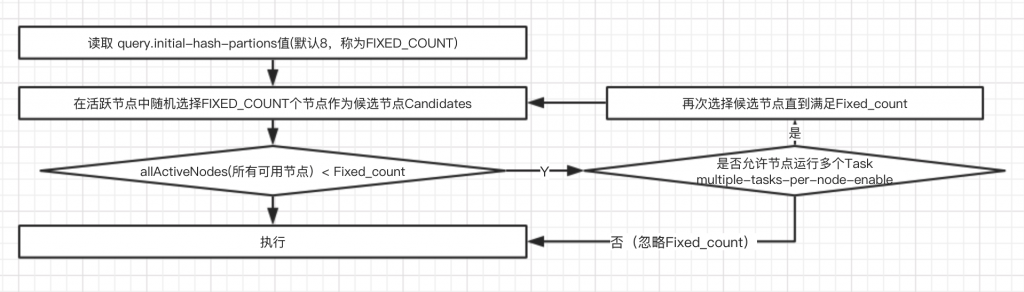
Single和Fixed Stage节点选择策略
均为随机选择,都调用NodeSelector.selectRandomNodes。Single Stage随机选择一个节点,而Fixed Stage具体过程如下:
-
Source Stage节点选择
每个查询请求会包含一个或多个SourceStage。根据Table的Split个数来决定节点的个数。
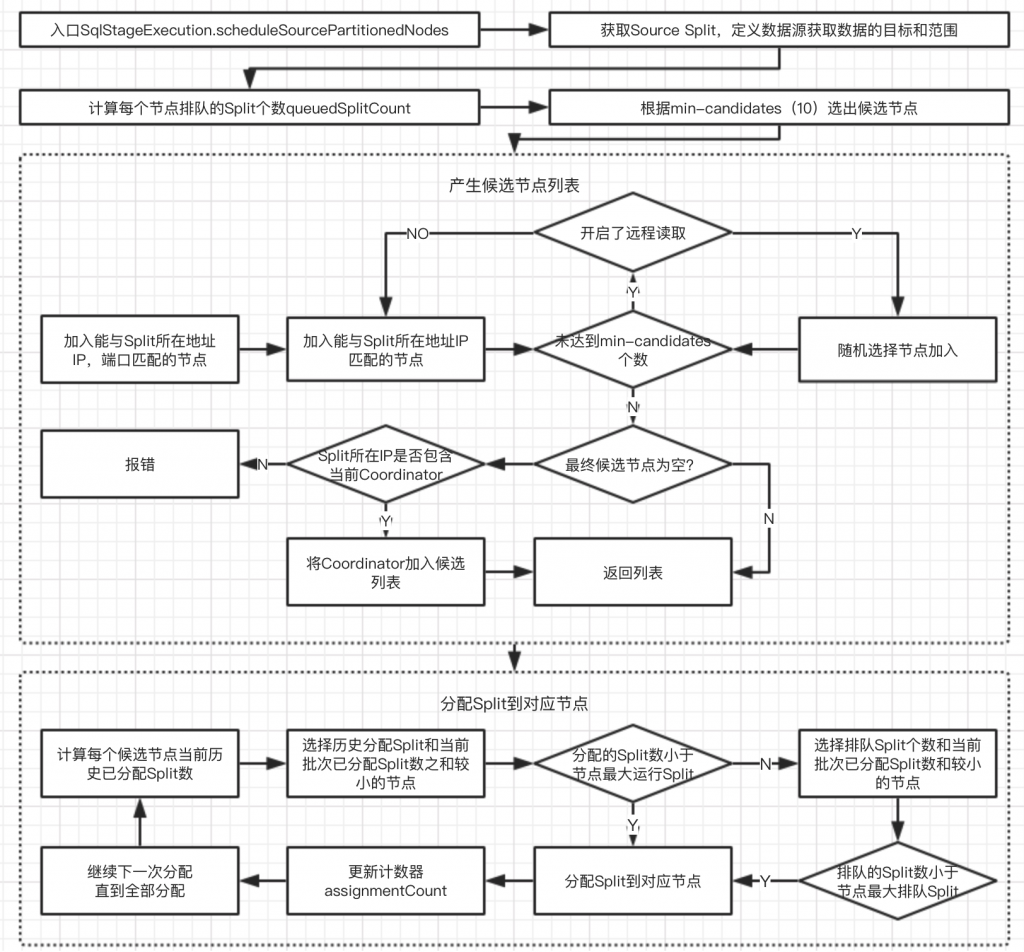
Presto通过尽量保证每个节点运行相对平均数量的Split来分配Task。这种策略可能带来两个问题
– Split可能无法分配到他所在的节点上,因为该节点已经运行的Split已经很多了
– 针对同时多个请求时,分配Split的策略只能保证全局的Split分布均匀,但不能保证单个Query的Split分布均匀。