
Druid
Druid是一个分布式支持实时分析的数据存储系统,为分析而生,在处理数据的规模和数据处理实时性方面比传统OLAP系统有显著的性能改进。与阿里的druid无关
Druid的三个设计原则
- 快速查询:数据预聚合+内存化+索引
仅存储经过预聚合的数据,如1分钟,1小时等,极大的提高了性能;使用Bitmap和各种压缩技术,并维护一些倒排索引,可以提高内存使用效率和AND,OR操作。
-
水平扩展:分布式数据+并行化查询
一般按照时间范围吧聚合数据进行分区处理,对于高维度数据还支持对Segment( < 2000万行)进行分区;历史Segment数据可以存储在本地磁盘,HDFS或云服务中;如果节点故障可借助ZK重新构造数据;Druid内置了容易并行化的集合操作,在直方图方面和去重查询方面采用近似算法保证性能,如HyperLoglog,DataSketches等
-
实时分析:不可变的过去,仅追加的未来
提供基于时间维度的数据存储服务,且每行数据一旦进入系统就不能改变;历史数据以Segment数据文件方式组织,需要查询时再装载到内存
技术特点
- 数据吞吐量大
- 支持流式数据摄入和实时
- 查询灵活且快
- 社区支持力度大
数据格式
-
数据源(类似数据库中表的概念,存放一类数据)
- 时间列:每个数据源都需要有的事件时间,是预聚合的主要依据
- 维度列:用于标识事件和属性,用于聚合
- 指标列:用于聚合计算的列,通常是关键量化指标
- 数据摄入
- 实时摄入:Kafka
- 批量摄入:HDFS、CSV等
- 数据查询
- 原生Json查询,Http接口
- 类SQL查询,支持大部分SQL语法(本书出版时还未支持)
数据分析软件分类
- 商业软件
- HP Vertica
- Oracle Exadata
- Teradata
- 时序数据库
- OpenTSDB
- InfluxDB
- 开源分布式计算平台
- Hadoop
- Spark
- 开源分析数据库
- Pinot
- Kylin
- Google Dremel
- Apache Drill
- Elasticsearch(ES)
- SQL on Hadoop/Spark
- Hive
- Impala
- Presto
- 数据分析云服务
- Redshift
- 阿里云
Druid架构
概览
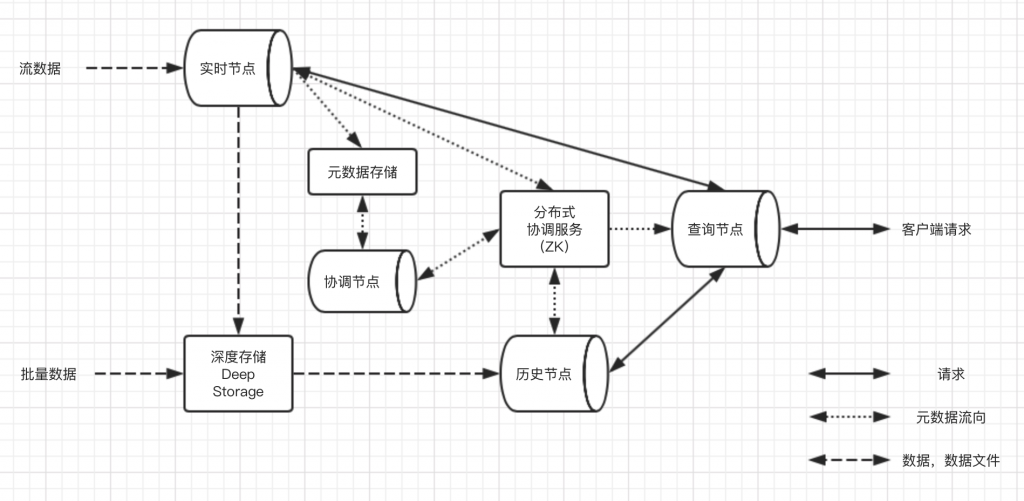
- Druid自身包含的节点
- 实时节点:摄入实时数据,生成Segment数据文件
- 历史节点:加载生成好的数据文件,供查询
- 查询节点:对外提供查询服务,并支持同时查询实时和历史节点,并合并结果
- 协调节点:负责历史节点的数据负载均衡,并管理数据生命周期
- Druid依赖的外部组件
- 元数据库:存储元数据信息,如Segment的相关信息。一般是Mysql
- 分布式协调服务:提供分布式一致性的组件,一般是Zookeeper
- 数据文件存储库:提供数据文件的存储功能,一般是本地磁盘或HDFS等
架构设计思想
索引
提高数据库查找速度的关键之一是减少磁盘的访问次数,并采用树形结构做索引
- 二叉查找树和平衡二叉树
二叉查找树在极端非平衡情况下查询效率会退化到O(N),因此尝试采用平衡二叉树;但是平衡二叉树的树高为 log_2 N,树高越高,查询次数越多越慢。同时,每次访问磁盘会读取多个扇区的数据,远大于单个树节点的值,造成浪费 -
B+树
传统关系型数据库的常用结构。- 每个树节点只放键值,不放数值,叶子节点存放数值,使得树高度较低
- 叶子节点按值大小顺序排序,带只想相邻节点的指针,方便区间数据查询
- 从叶子节点开始更新,以较小的代价实现自平衡
- 缺点是随着数据插入,叶子节点会分裂,导致连续数据被存放在不同的物理磁盘块上,导致较大的IO开销
- 日志结构合并树(LSM)
日志结构的所有方式的将磁盘看做一个大的日志,每次都将新数据和索引结构添加到最末端;LSM通过将数据文件预排序解决了日志结构随机读性能差的问题。- 使用两颗树来存储数据,其中一部分数据结构存在内存(C_0 Tree,memtable),负责插入更新和读请求,并在内存中进行排序;另一部分写在磁盘(C_1 Tree,sstable),负责读操作,有序且不能更改
- 使用日志文件做数据恢复保障,所有操作记录先写Log,再写memtable,最后冲写到sstable
- 定期合并小sstable以减少sstable数量,对每个sstable使用布隆过滤器,以加速数据存在与否的判定
总体架构
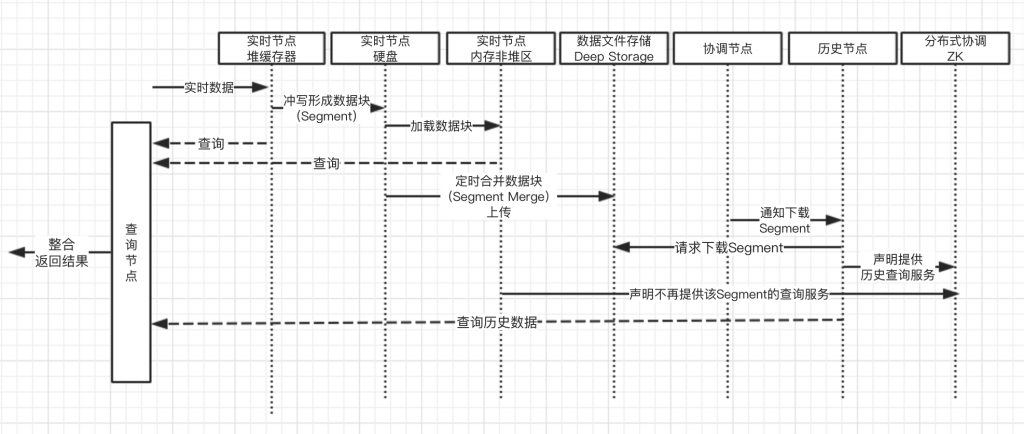
Druid对命令查询职责分离模式(CQRS)的借鉴,优势如下:
- 类LSM-tree使得数据高速写入,并提供快速实时查询
- 不提供已有数据更改,虽然降低数据完整性保障,但是减少了工作量,提高性能
- 对CQRS模式的借鉴使得组件职责分明,易于优化