生成查询执行计划(下)
执行计划的生成
执行计划节点
执行计划树中的节点分为以下几种类型
- AggregationNode
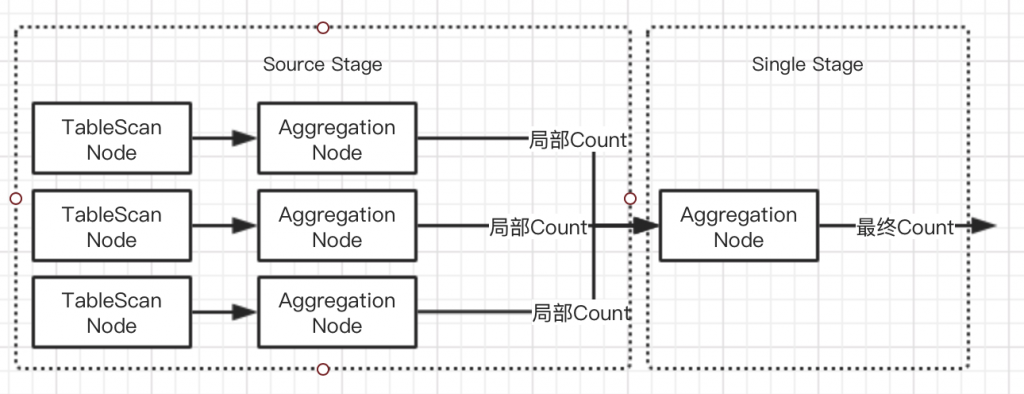
用于聚合操作的节点,在执行计划优化前所有的聚合节点都是单点聚合,优化后拆分为为其他两种- FINAL 最终聚合
- PARTIAL 局部聚合
- SINGLE 单点聚合
- DeleteNode 用于DELETE操作的节点
- DistinctLimitNode
用于SELECT Distinct ... FROM ... LIMIT ...类型SQL的节点 - ExchangeNode
用于执行在不同Stage中交换数据的节点,出现在逻辑执行计划中 - FilterNode 过滤操作的节点
- IndexJoinNode 进行IndexJoin的节点
- IndexSource 与Index Join配合,执行数据源读取操作的节点
- JoinNode 执行Join的节点
- LimitNode
- MarkDistinctNode
用于执行 Count(Distinct …)的节点 - OutputNode 用于输出最终结果
- ProjectNode 用于列映射,将ProjectNode下层节点输出列映射到上层节点的输入列
- RemoteSourceNode 用于分布式执行计划中不同Stage之间交换数据;出现在分布式执行计划中
- RowNumberNode 用于处理窗口函数row_number()
- SampleNode 用于处理抽样函数
- SemiJoinNode 用于处理执行计划生成中产生的SemiJoin
- SortNode 排序
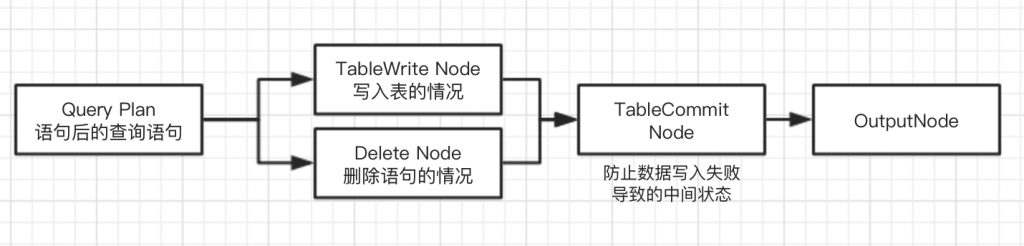
- TableCommitNode
用于 Create Table As Select , Insert , Delete语句进行Commit - TableScanNode 用于读取表的数据
- TableWriteNode 用于向目的表写入数据
- TopNNode 用于取排序后的前N条数据,使用效率更高的TopN算法(而不是全局排序取前十)
- TopNRowNumberNode 用于处理row_number()取前N条记录的结果
- UnionNode
- UnnestNode
- ValuesNode
- WindowNode 用于窗口函数
SQL执行计划
LogicalPlanner负责SQL语句执行计划的生成,根据不同类型的SQL生成不同的执行计划,然后对其应有优化器
- TableWritePlan
Create Table As Select 语句和Insert语句都会生成这个计划 - DeletePlan
Delete语句会生成这个Plan - QueryPlan
所有Relation类型的SQL都会生成QueryPlan,并由RelationPlanner分析并生成查询执行计划
Relation执行计划
针对Relation类型的SQL语句生成执行计划
- Table
- 如果Table是With定义的,或者Table本身是个View,则处理其关联的查询生成计划
- 如果是普通的表,则构建TableScanNode
- AliasedRelation 处理AliasedRelation关联的relation,并生成执行计划
- SampledRelation
- 处理关联的Relation,生成执行计划树
- 构建一个SampleNode在上述树之上
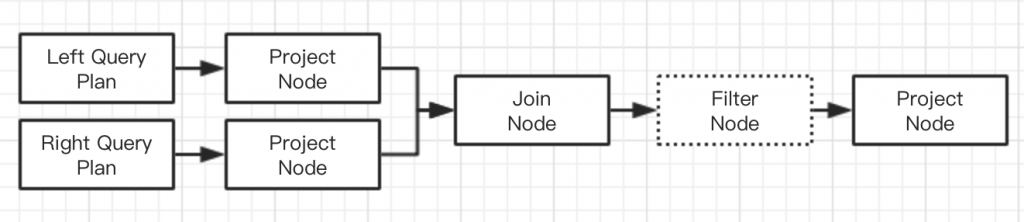
- Join
- 处理左侧的Relation,生成左侧执行树
- 如果右面是Unnest且Join类型是Cross Join或者 Implicit Join,则根据Unnest构造一个UN呢收入Node以及一个ProjectNode,添加到左侧执行计划上
- 如果右边不是Unnest,则生成右侧执行计划树
- 提取Join条件中的表达式,在两侧执行计划树上添加ProjectNode
- 如果是InnerJoin,则构造Cross类型的JoinNode,并添加一个FilterNode,条件为连接条件
- 如果不是InnerJoin,则构造对应类型的JoinNode
- 如果Join某侧有泊松抽样,则再在以上计划树上再加一个ProjectNode
- TableSubQuery 处理子查询的语句并返回执行计划
- Query 使用QueryPlanner处理,返回执行计划
- QuerySpecification 使用QueryPlanner处理,返回执行计划
- Values 获取每一项的值,并构造ValuesNode
- Unnest 只处理常亮类型的Unnest语句,其他在visitJoin中已经被处理
- 首先根据常量构建ValuesNode,再在这之上构造UnnestNode
- Union 分别处理所有子语句,并最后在这些子语句的根节点上构造一个UnionNode
Query执行计划
- Query
planQueryBody针对QueryBody生成Relation执行计划appendSemiJoins处理In子句的查询,添加SemiJoinNodeproject为执行计划添加projectNode,映射字段到上层方便处理sort添加SortNode和TopNNodeproject映射整个查询的输出列limit添加LimitNode
- QuerySpecification
- planFrom处理From语句,如果不存在From则直接构造ValuesNode返回,否则使用RelationPlanner处理
- appendSemiJoins同上
filter为Where条件添加FilterNodeaggregate添加聚合操作filter为Having子句添加FilterNodewindow处理窗口函数projectdistinct处理Distinct,添加AggregationNodesortprojectlimit
- SemiJoin
- 为IN左侧的查询添加ProjectNode,将其作为列输出
- 为In子句生成查询计划树
- 在以上两个计划树之上添加SemiJoinNode
- Aggregate操作
- 获取聚合函数参数和GroupBy表达式,并构造ProjectNode
- 对聚合函数和GroupBy进行分析
- 如果含有Distinct,则构造MarkDistinctNode
- 根据上述结果构造AggregationNode
- Window函数
- 获取Partition By 和 Order By 表达式,并构造ProjectNode
- 分析上述语句和窗口函数
- 生成WindowNode
执行计划优化
- ImplementSampleAsFilter
将BERNOULLI抽样(伯努利抽样)的SampleNode改写成FilterNode(rand() < SampleRatio) - CanonicalizeExpressions
将表达式进行标准化,主要有以下几种:- Is Not Null 改写成 Not (Is Null)
- If 改写成 Case when
- 处理时间函数
- SimplifyExpression
将表达式进行简化和优化,具体参见ExpressionInterpreter - UnaliasSymbolReferences
去除ProjectNode中的无意义映射。对于不带表达式的直接映射,不再映射为新的列名,而是直接将列映射出去 - PruneRedundantProjections
用于去除多余的ProjectNode(如果里面都是列直接映射) - SetFlatteningOprimizer
用于扁平化Union语句的执行计划树,使得树的层数减少 - LimitPushDown
用于将Limit条件进行下推,减少下游数据处理量- 如果Limit为0,则直接返回ValuesNode
- 下推到AggregationNode时,如果是Distinct聚合,则将其替换为DistinctLimitNode
- 下推到TopNNode时,构造一个新的TopNNode,N取Limit和原TopNNode中的N最小值
- 下推到SortNode时,替换为TopNNode
- 下推到Union时,在每一个子节点上添加LimitNode
- PredicatePushDown
用于将过滤条件进行下推,减少下游数据处理量- 经过ProjectNode时,仅下推确定性的过滤条件,否则添加一个FilterNode
- 经过UnionNode时,在所有子查询应用Filter
- 对于Join,下推到对应的表的子查询上,如果Where条件同时是Join条件,则下推到两种表的子查询上
- MergeProjections
用于将连续的ProjectNode 进行合并 - ProjectionPushDown
用于将UnionNode之上的ProjectNode下推到UnionNode下,可以减少UnionNode处理的列数,提高效率 - IndexJoinOptimizer
用于将Join优化为IndexJoin - CountConstantOptimizer
用于将Count(constant)改写成count(*)。后者更易于根据不同数据源进行优化 - WindowFilterPushDown
用于处理row_number()函数中排序取N条的结果,将原有执行计划中的WindowNode替换为TopNNodeRowNumberNode,避免全局排序 - HashGenerationOptimizer
在执行计划阶段提前计算Hash值 - PruneUnreferencedOutputs
用于去除ProjectNode中不在最终输出中的列 - MetadataQueryOpeimizer
优化只对表分区字段进行的聚合操作,使之变成针对元数据的查询 - SingleDistinctOptimizer
将单一Distinct聚合优化为GroupBy,可以尽量进行本地聚合,减少后续数据传输 - BeginTableWrite
根据SQL类型调用beginCreate/beginInsert然后构造CreateHandle/InsertHandle用于TableWriteNode的后续操作,理论上不属于优化器 - AddExchanges
根据逻辑执行计划生成分布式执行计划, - PickLayout
根据SQL语句选取最合适的TableLayout。根据SQL所需要的表的列,分区等构造最合适的表组织结构
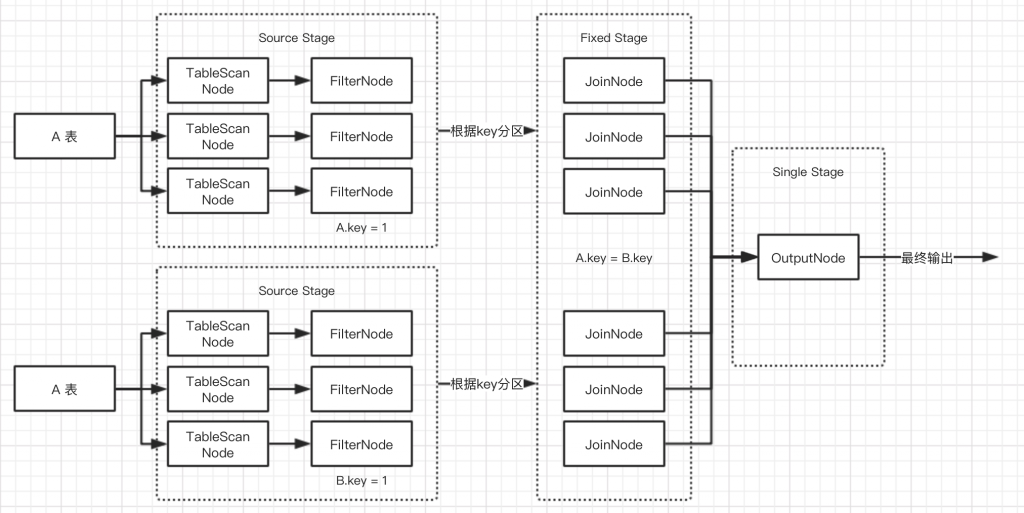
执行计划分段
最后对执行计划进行分段。见(1)
– Source 包括TableScanNode,ProjectNode以及FilterNode等
– Fixed 局部聚合,局部Join,局部数据写入等
– Single 在Fixed之后,在单个节点上运行,汇总所有处理结果(包括全局排序)
– Coordinator_only 对Insert和Create table进行Commit(TableCommitNode)
示例
Count的情况
Join的情况