
DW、BI维度建模初步
DW和BI的目标
- 系统要能方便的存取信息
简单、快捷 - 系统必须以一致的形式展现信息
数据可信,拥有一致的公共标识和定义,度量名称独立性 - 系统必须能适应变化
当业务问题发生变化或有新数据添加时,必须不能改变和破坏已存在的数据 - 系统必须能够及时的展现信息
- 系统必须成为保护信息财富的安全堡垒
对机密数据的访问空值 - 系统必须成为提高决策制定能力的权威和可信的基础
数据正确以支持决策制定。系统最重要的输出是基于分析证据所产生的决策 - 系统成功的标志是业务群体接受此系统
维度建模简介
传统关系型数据库中一般应用3范式(3NF,规范化模型)建模,有点如下:
– 消除冗余
– 规范化
– 应用在操作型过程中,对事务的更新和插入仅触及数据库的单一地方
维度建模解决了关系型数据库中常用的3范式建模带来问题:
– 规范化模型太过复杂
– 用户难以理解,检索
– 查询的复杂性使得关系型数据库系统无法承受
星型模式与OLAP多维数据库
在关系数据库管理系统中实现的维度模型称为星型模型;在多维数据库环境中实现的维度模型通常称为联机分析处理多维数据库(OLAP)
通常推荐将详细,原子的信息加载到星型模式中,然后将OLAP多维数据库移植到星型模型上。
用于度量的事实表
事实表存储业务过程中事件的度量结果。应尽量将来源于同一个业务过程的底层度量结果存储于一个维度模型中。应该允许多个组织的业务用户访问同一个单一的集中式数据库,确保其使用一致的数据
- 事实:表示某个业务度量
- 事实表中的每一行对应一个度量时间,每行中的数据是一个特定级别的细节数据,称为粒度
- 事实通常使用连续值描述,这样有助于区分到底是事实还是维度属性的问题
- 不要再事实表中存储冗余的文本信息,除非其对于每行来说是唯一的,否则应放入维度表中
- 不要采用0来表示没有活动发送而填充表
- 事实表的粒度可划分为三类:事务,周期性快照,累计快照
- 事实表具有2个及以上的外键,且外键满足参照完整行(可与维度表中的主键正确匹配)
- 事实表的主键常称为组合键,由多个外键唯一表示每一行事实
- 事实表表示多对多关系,其他表称为维度表
用于描述环境的维度表
维度用于描述业务过程度量事件相关的文本环境,用来描述5W1H有关的事件
- 维度表通常有多列,即包含多个属性
- 维度表由单一主键定义,用于和事实表关联
- 维度属性可作为查询约束(WHERE),分组(GROUPBY),报表表示的主要来源
- 维度属性对BI/DW系统的可用性和可理解性有重要作用
- 属性应包含真实使用的词汇而不是缩写或代号
- 维度提供数据的入口点,提供所有分析的最终标识和分组
- 如果一个数值列包含多个值且作为计算的参与者的度量,则可能为
事实;如果是对具体值的描述,是常量,约束,标识则有可能为维度 - 维度通常以层次关系表示,层次描述信息存在冗余,如在产品的维度表中存储产品所属的品牌和类别信息
- 维度表通常不一定要满足第三范式;通常存在多对一关系
- 一般对维度表存储空间的权衡往往需要管制简单性和可访问性
星型模式中维度和事实的链接
维度模型表示每个业务过程包含事实表,事实表存储事件的数值化度量,维度表包含事件发生时包含的文本环境。类似的星装结果称为星型连接
- 简单性和对称性使得维度模式易于理解和不易出错,同样提高了性能
- 维度模型适于变化,当采用新的模式分析数据时,不需要调整模式
- 粒度最小的原子数据具有最多的维度,可以满足用户的任意查询
- 只要维度的单一值被定义到已存在的事实表中,就可以新增维度
- 只要细节级别与当前事实表一致,就可以新增新的事实 而不需要重新加载数据
Kimball的DW/BI架构
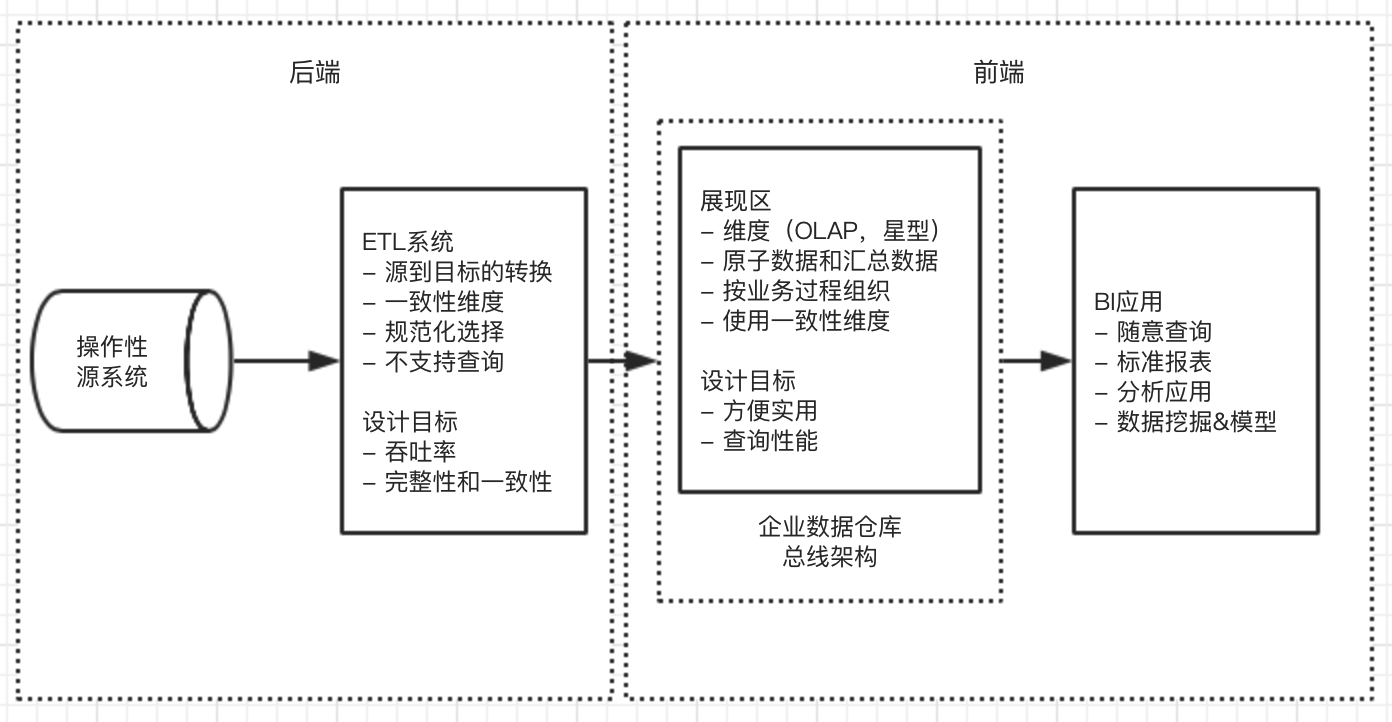
操作型源系统
可以认为处于数仓之外。主要关注处理性能和可用性,几乎不能控制这些系统中的数据格式和内容。
ETL(获取-转换-加载)系统
ETL系统从源系统获取数据后需要进行一系列转换操作:
– 清洗数据(消除错误,解决冲突,解析为标准格式)
– 合并来自不同源的数据
– 复制数据等
– 建立诊断元数据
– 建立业务过程以改进源系统的数据质量
ETL通过上述操作增加数据的利用价值
最后步骤是实际构建和加载数据到展现区域的目标维度模型中,并划分事实和维度。子系统关注维度表的处理,包含代理键分配,查找代码,拆分组合列,链接3范式表称为扁平的维度表等。
当维度模型中的维度表和事实表被更新、索引、适当聚集并确保质量后,业务用户就可以开始使用这部分数据。
ETL中一般不需要建立规范化的数据表,而是直接考虑 可理解性 和 性能 这两个目标
用于支持商业智能决策的展现区
展现区用于组织、存储数据、支持用户查询。
1. 数据应以维度模型来展现
2. 必须包含详细的原子数据,以满足用户无法预期的详细查询
- 展现区的数据可以围绕业务过程度量事件来构建,维度模型应对应物理数据获取事件。
- 必须使用公共的、一致性的维度建立维度结构,以实现企业数据仓库总线架构
- 展现区中的数据必须是维度华的,原子的。数据不应该按照个别部门需要的数据来构建
商业智能应用
BI应用
与餐厅类比的Kimball架构
- 后端 -> 餐馆后厨
- 注重高效,质量,一致性和完整性
- 应与顾客隔离,不能被任意的问询打扰
- 前端 -> 用餐区
- 菜单 -> 元数据等告诉用户 什么是可用的
- 数据要满足需求
- 价格需要被用户接受
其他DW/BI架构
独立数据集市架构
即为企业的每个独立部门分别建立分析数据仓库,不考虑跨部门的信息共享和集成。即烟囱开发。不推荐
辐射状企业信息工厂Inmon架构
在ETL部分使用EDW满足三范式。将原子数据固定为规范化架构,仅提供统计类数据发布,不能很好的满足用户
混合辐射状架构和Kimball架构
适用于已有EDW的中间层的情况下搭建Kimball架构
维度建模神话(误解)
- 维度建模仅包含汇总数据
维度建模可以提供原子级的最细粒度数据,汇总数据只在针对公共查询时能比粒度数据提供更好的性能 - 维度模型是部门级而不是企业级
维度模型应该是围绕业务过程组织,维度应是企业统一维度 - 维度模型是不可扩展的
维度模型可以方便的新增事实和维度 - 维度模型仅用于预测
维度模型设计应该是适应变化的。 - 维度模型不能被集成
如果遵守企业总线结构,则维度模型大部分可以被集成。只要维护ETL系统中的一致性维度和主数据