从SQL到RDD
// 创建SparkSession类。从2.0开始逐步替代SparkContext称为Spark应用入口
var spark = SparkSession.builder().appName("appName").master("local").getOrCreate()
//创建数据表并读取数据
spark.read.json("./test.json").createOrReplaceTempView("test_table")
//通过SQL进行数据分析。可输入任何满足语法的语句
spark.sql("select name from test_table where a > 1").show()
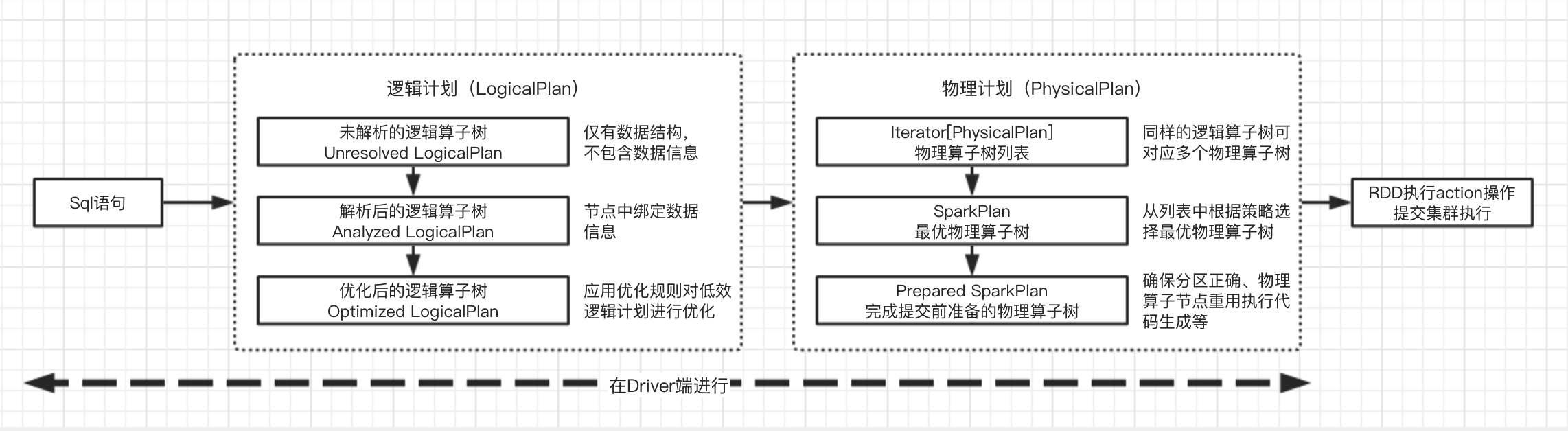
SQL转换步骤
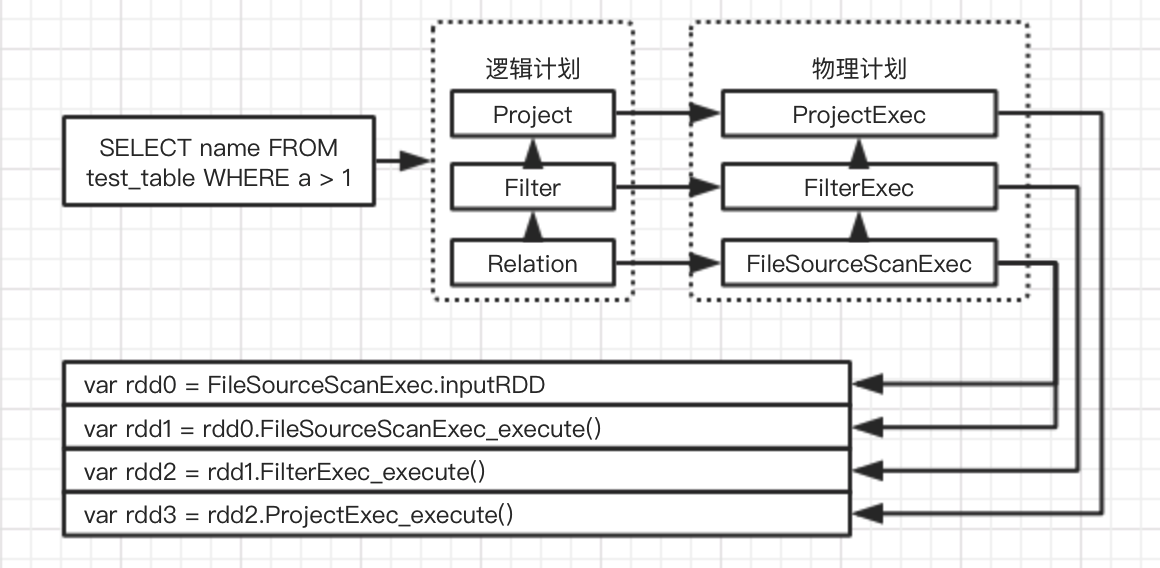
实际转换过程
InternalRow体系
用来表示一行数据的类,根据下标来访问和操作元素,其中每一列都是Catalyst内部定义的数据类型;物理算子树产生和转换的RDD类型为RDD[InternalRow];
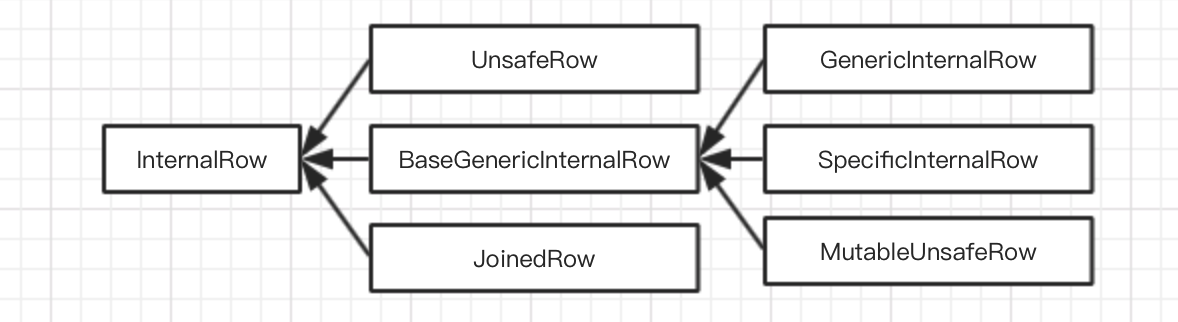
- BaseGenericInternalRow 实现了InternalRow中所有定义的
get类型方法,通过调用此类定义的genericGet虚函数进行,实现在下级子类中- GenericInternalRow 构造参数是Array[Any],采用对象数据进行底层存储,不允许通过set进行改变
- SpecificInternalRow 构造函数是Array[MutableValue] ,运行通过set进行修改
- MutableUnsafeRow 用来支持对特定列数据进行修改
- JoinedRow 用户Join操作,将两个InternalRow放在一起形成新的InternalRow
- UnsafeRow 不采用Java对象存储方式,避免GC的开销。同时对行数据进行特殊编码使得更高效(Tungsten计划)。
TreeNode体系
TreeNode是SparkSQL中所有树节点的基类,定义了通用集合操作和树遍历接口
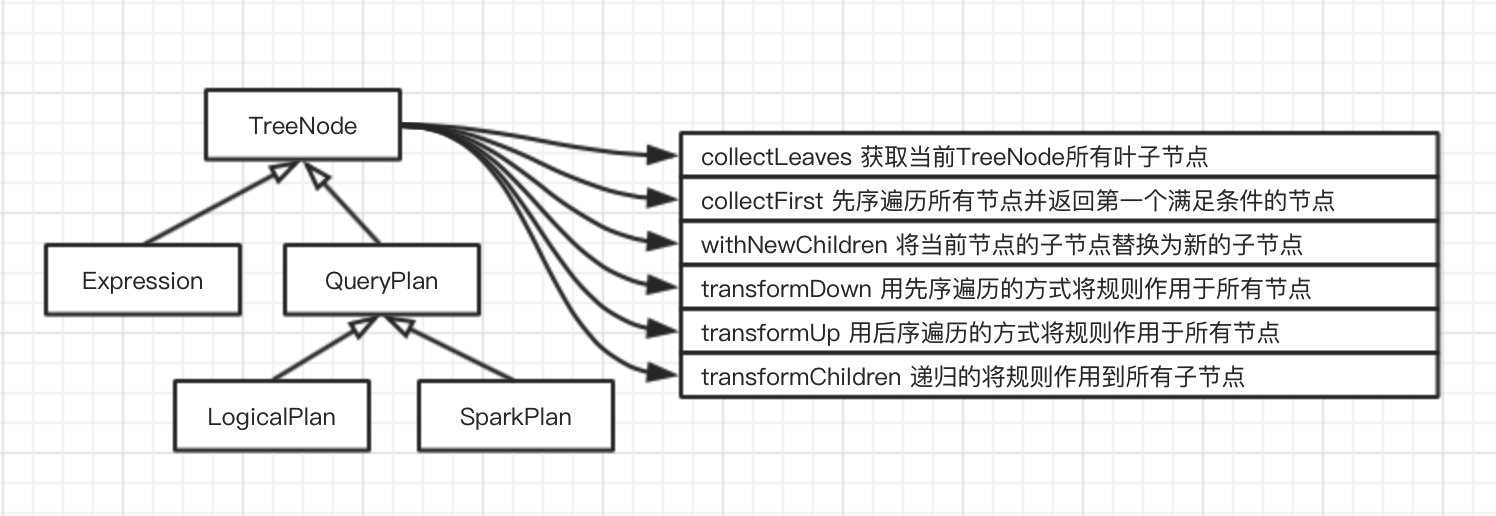
- Expression是Catalyst的表达式体系
- QueryPlan下包含逻辑算子树和物理执行算子树两个子类
Catalyst还提供了节点位置功能,根据TreeNode定位到对应SQL字串中的位置,方便Debug
Expression体系
一般指不需要触发执行引擎也能直接计算的单元,如四则运算,逻辑、转换、过滤等。主要定义5个方面的操作:
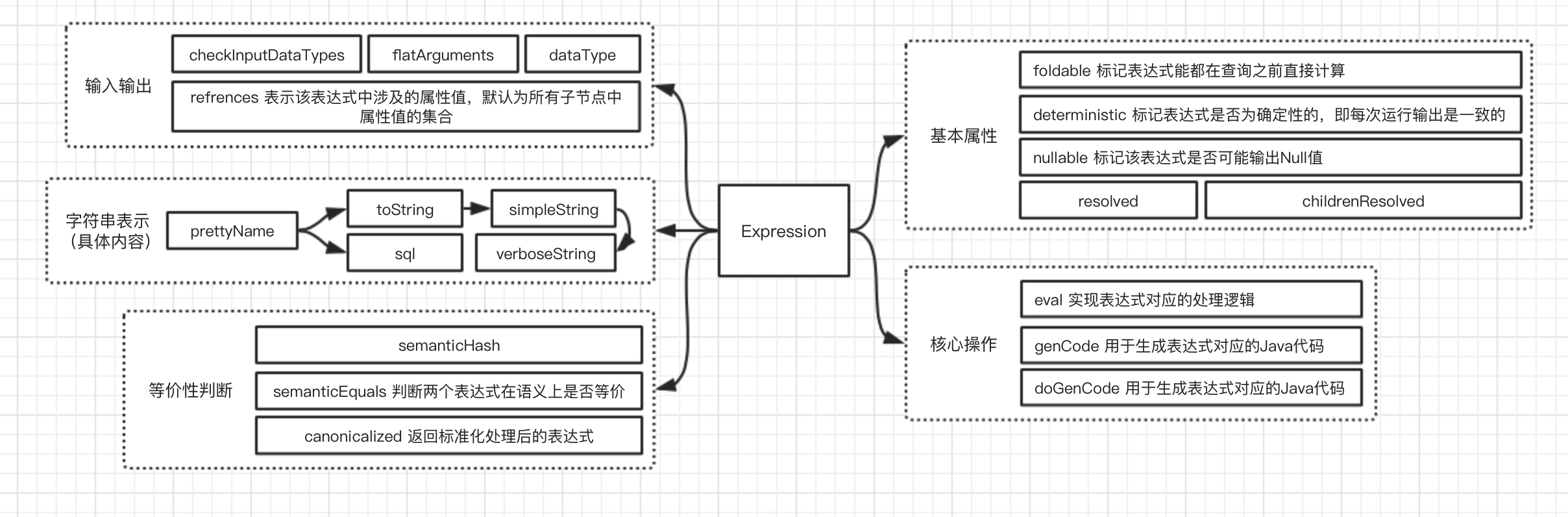
Expression也是TreeNode 的子类,因此可以调用所有TreeNpde方法,也能通过多级Expression组成复杂表达式。下面列举常用Expression:
- Nondeterministic接口(deterministic=false;foldable=false 具有不确定性的Expression,如Rand())
- Unevaluable接口 非可执行表达式,调用eval会抛出异常。主要用于未被逻辑计划解析或优化的表达式
- CodegenFallback接口 不支持代码生成的表达式,一般用于第三方实现的无法生成Java代码的表达式(如Hive的UDF),在接口中实现具体调用方法
- LeafExpression 叶子节点类型的表达式,不包含任何子节点,如Star,CurrentData
- UnaryExpression 一元类型表达式,输入涉及一个子节点,如Abs
- BinaryExpression 二元类型表达式
- TernaryExpression 三元类型表达式
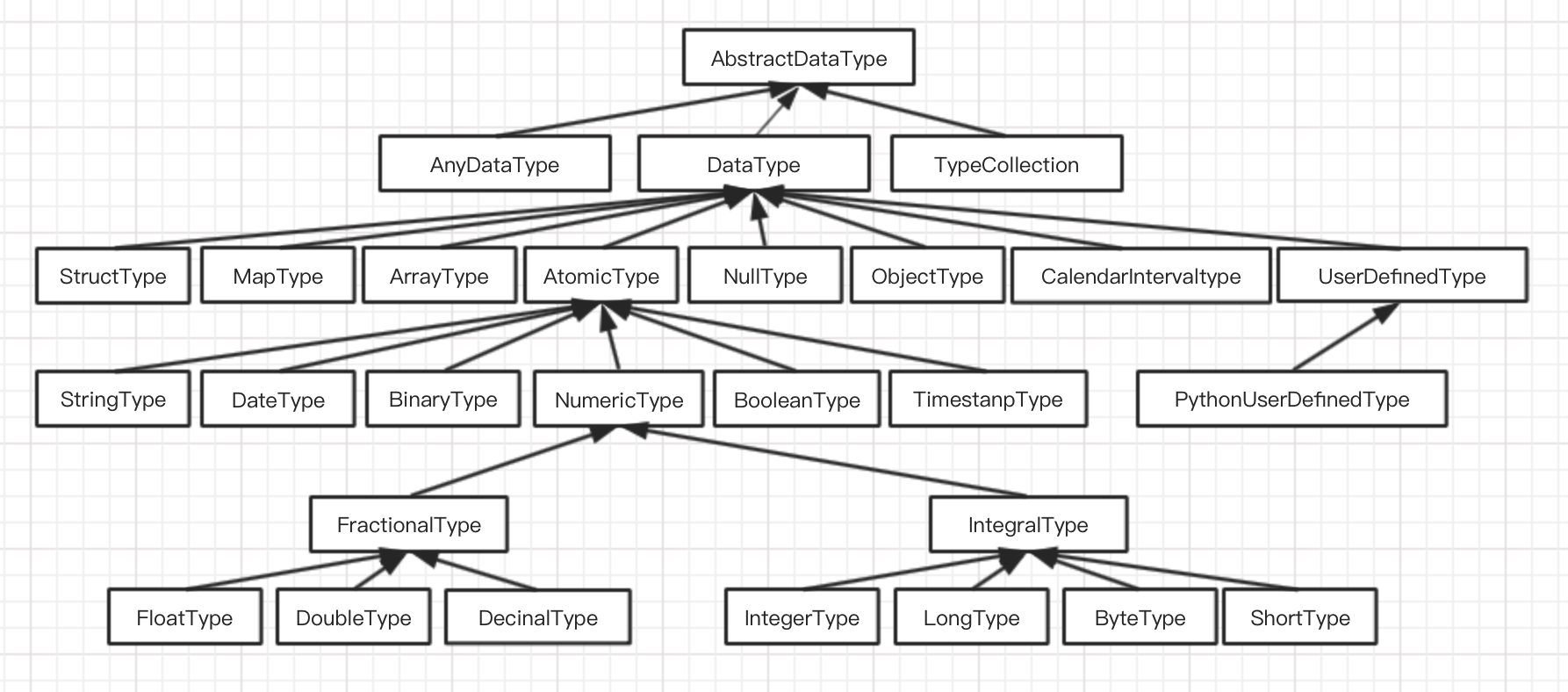
内部数据系统