
CTR
CTR,Click-Through-Rate,也就是点击率预估 ,指的是精排层的排序。所以 CTR 模型的候选排序集一般是千级数量。
CTR 模型的输入(即训练数据)是:大量成对的 **(features, label) **数据。
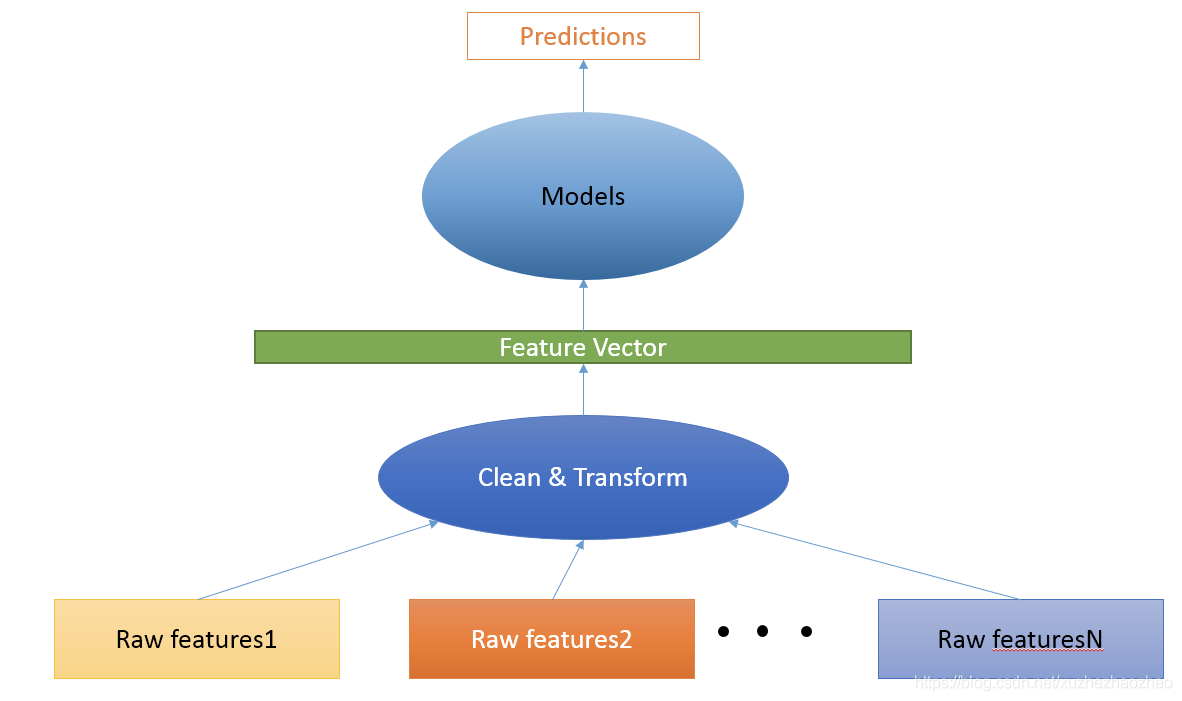
特征处理
- 离散型特征使用** ****one-hot** 或** embedding**;
- 连续型特征可以不处理,也可以 分段离散化 ,再使用 one-hot 编码;
- 实际中最主要的工作都在从原始特征生成特征向量这一步,这一步也叫数据处理,这一步的好坏决定了天花板的高度。至于模型,其实主要工作是调参,包括模型的种类也是一个参数,其实是最简单的一步,只是可能比较费时费力。
- 当然,实际中还有可能遇到超大规模数据的问题,这需要分布式训练,甚至最后的模型没办法在单机中加载,也需要分布式。
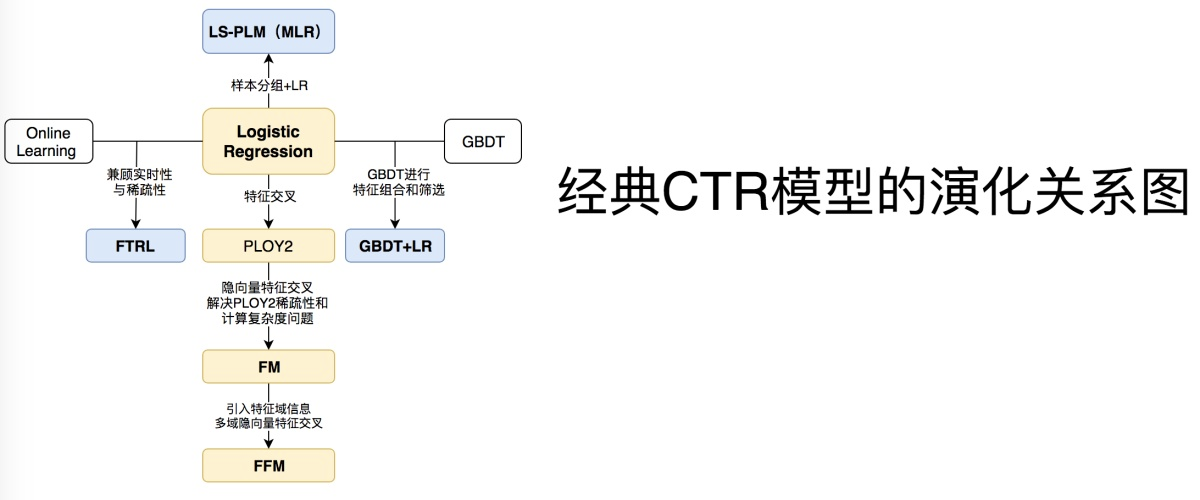
常用模型
LR
对向量的每一个维度赋予一个权重,然后加权求和,又因为输出需要是 0-1 之间的浮点数,所以求和之后套用一个 sigmoid 函数,将值域压缩在 0-1 之间
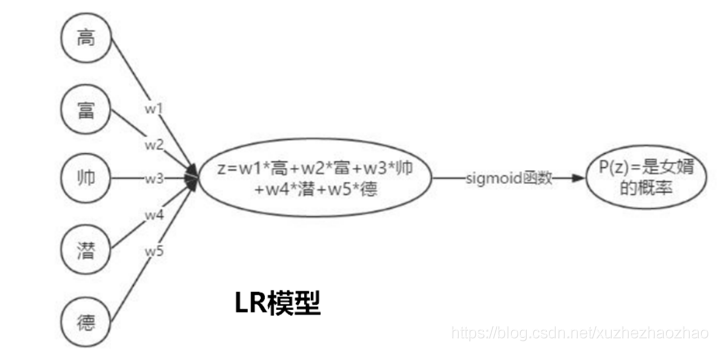
* 优点:简单,容易实现;
* 缺点:易学难精,需要 手工构造特征(特征交叉) ,需要 大量领域内知识 ;另外,LR 非常适合处理离散特征,而对于连续特征,需要手工分段或归一化处理。
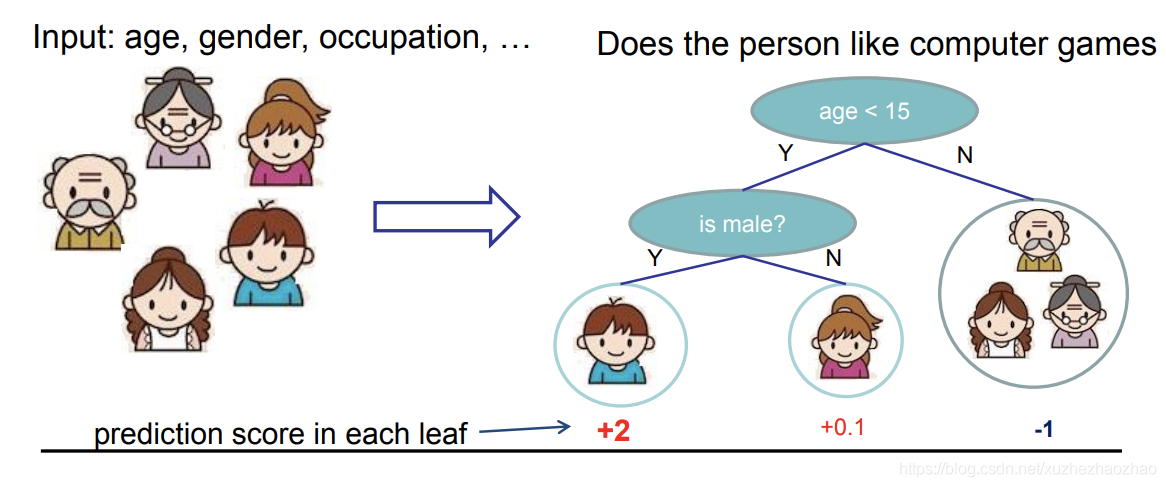
GBDT
Gradient Boosting Decison Tree,梯度提升决策树。是算法比赛中使用最多的模型之一。
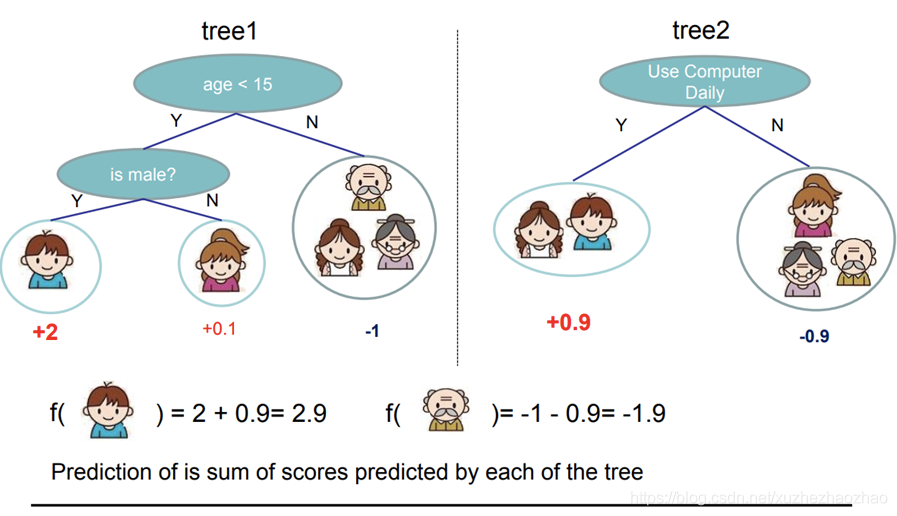
核心思想:用回归树(CART 树)来 拟合残差 。
GBDT 使用的是 CART 树,是回归树的一种,如下图所示,回归树最后的预测结果是一个浮点数;GBDT 使用多颗 CART 树,每棵树都是拟合前面树模型的残差。
- 优点:得益于 CART 树,可以方便地处理连续特征;另一个重要用处是输出特征重要性;
- 缺点:比较容易过拟合,不是很适合处理离散特征。
- GBDT虽然具备一定的组合特征的能力,但是组合的能力十分有限,远不能与dnn相比。
GBDT + LR
GBDT + LR 。核心思想是 利用 GBDT 来自动对连续特征离散化 。
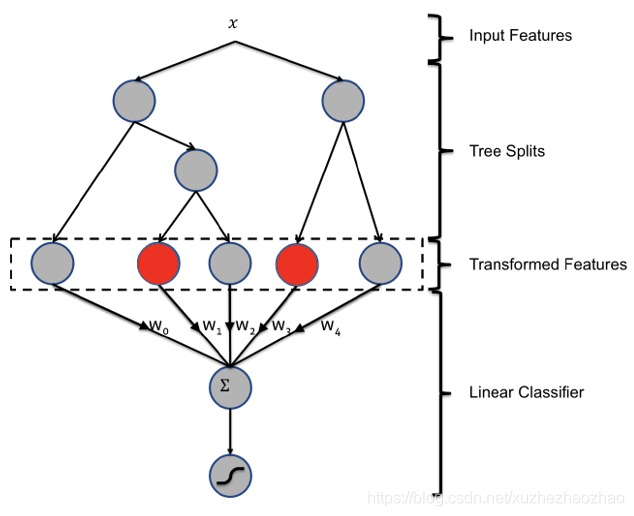
通过 GBDT 中叶子节点的索引位置获得输入特征的离散化编码,可以看到,结果分别落在第 2 和第 1个叶子节点,转换特征编码为 [0, 1, 0] + [1, 0],即 [0, 1, 0, 1, 0],之后再将该编码输入到 LR 中训练。
- 优点:无需对连续特征手工处理;
- 缺点:需要预训练 GBDT 模型;
FM (Factorization Machines)
FM 解决全交叉导致权重爆炸的核心思想是:权重的分解和 共享 ,这也是其命名的由来。
FM 提出将交叉特征的权重 wij 做一次分解,分解为两个隐向量(lantent vector)的乘积,如下:
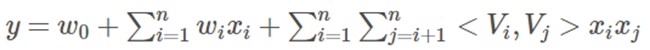
其中,
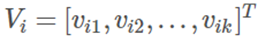
< ,> 代表向量乘法,k 是超参数,即 lantent vector 的维度。
光分解还是不够,因为权重爆炸的问题并没有解决,所以接下来就是共享隐向量:每个原始特征都对应同一个隐向量,这个隐向量是被所有该特征的交叉特征权重共享的。这样一来,若有 N 个基本特征,共享之后的参数量就为 Nk,而不是 NN 了,一般情况 k << N。
将交叉特征权重分解为两个隐向量的乘积是 FM 的思想精华所在,通过这种方式,我们可以对原始特征进行全交叉,省去了手工交叉特征的麻烦。
FFM (Field-aware Factorization Machines)
FFM 可以理解为 FM 的一个 trick:跟 FM 的全局共享不一样,FFM 中隐向量不是全局共享的,而是在 特征域内共享
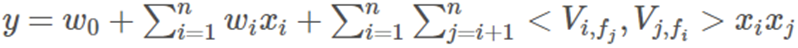
其中,f_j 是第 j 的特征所属的字段。如果隐向量的长度为 k,那么 FFM 的二次参数有 n_f_k 个,远多于 FM 模型的 n_k 个
MLR
MLR即混合逻辑回归,由阿里团队提出,是对LR的推广,采用分而治之的策略:如果分类空间本身是非线性的,按照合适的方式将空间分为多区域,每个区域用线性的方式进行拟合,最后MLR的输出就变成了多个子区域预测值的加权平均
MLR模型在大规模稀疏数据上实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;同时模型复杂度可控,有较好的泛化能力,同时保留了LR模型的自动特征选择能力。
MLR的难点在于目标函数非凸非光滑,使得传统的梯度下降算法并不适用。需要预训练,可能出现不收敛的情况。同时和LR相同也需要较大的特征工程处理。
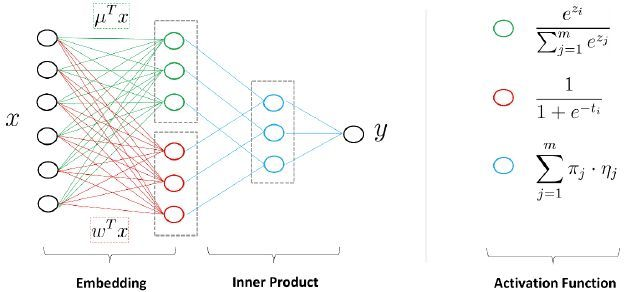
f(x)=\sum_{i=1}{m} {softmax(x|\mu) ·logistic(wTx)=\sum_{i=1}{m}{\frac{e{\mu_iTx}}{\sum_{j=1}{m}{e{\mu_jTx}}}}}·\frac{1}{1+e{-wTx}} m为分片数(m=1,即LR模型)
- softmax(x|\mu)=\frac{e{\mu_iTx}}{\sum_{j=1}{m}{e{\mu_j^Tx}}} 是聚类参数,决定分片空间的划分,即某个样本属于特定分片的概率
- logistic(w^Tx)=\frac{1}{1+e^{-w^Tx}} 是分类参数,决定分片空间内的预测
- 最终模型预测值为所有分片对应的子模型的预测值的期望
相当于将X进行聚类,每一个聚类单独训练一个LR
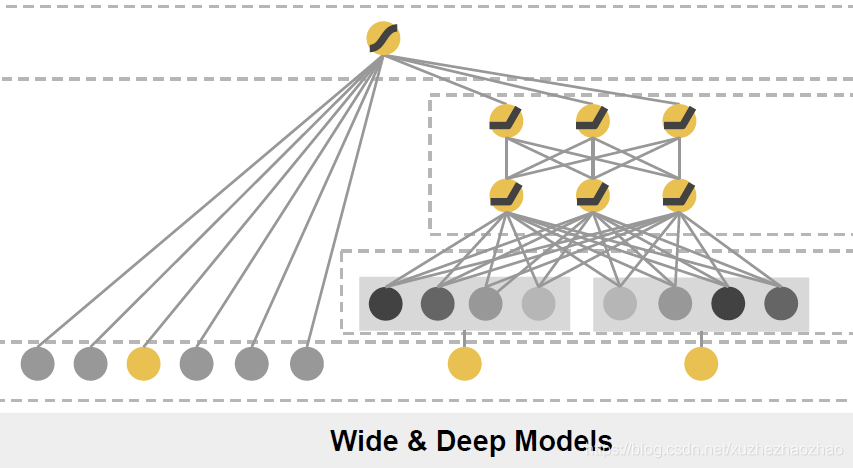
Wide & Deep
Wide 部分通过手工交叉特征提取低阶特征,Deep 部分通过神经网络提取高阶特征。
Wide 部分等价于 LR,deep 部分为全连接网络
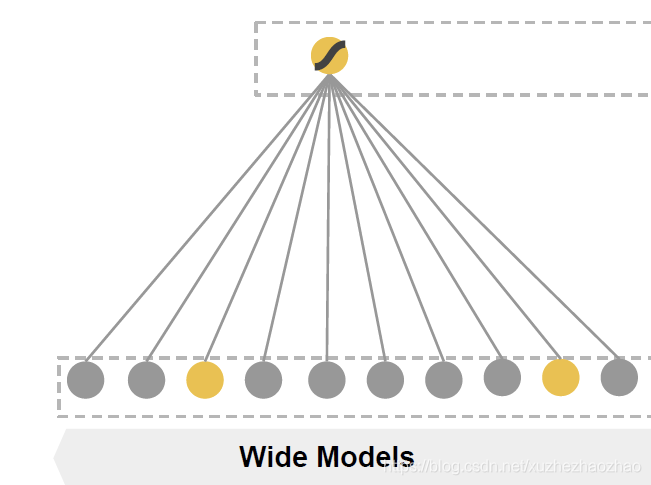
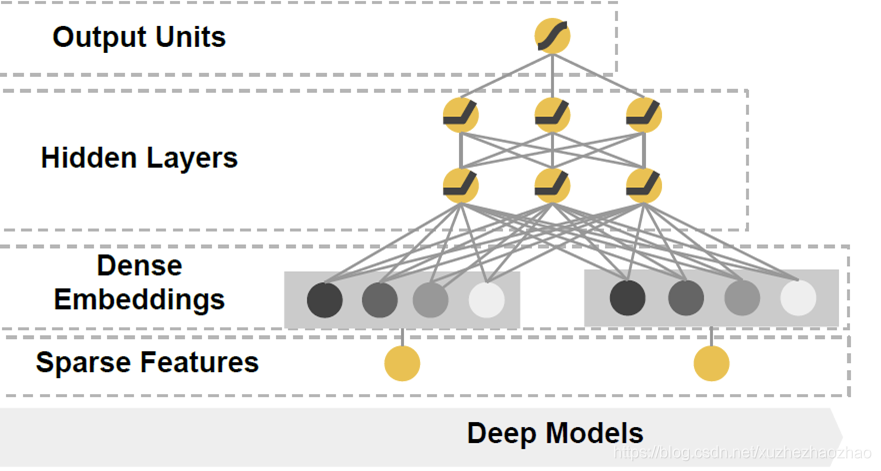
wide&deep 是思想非常重要,它首次将神经网络引入了 CTR 模型,并且将模型分为 wide 和 deep 两部分的思路也启发了很多人,后面的模型本质上都可以算它的变种。
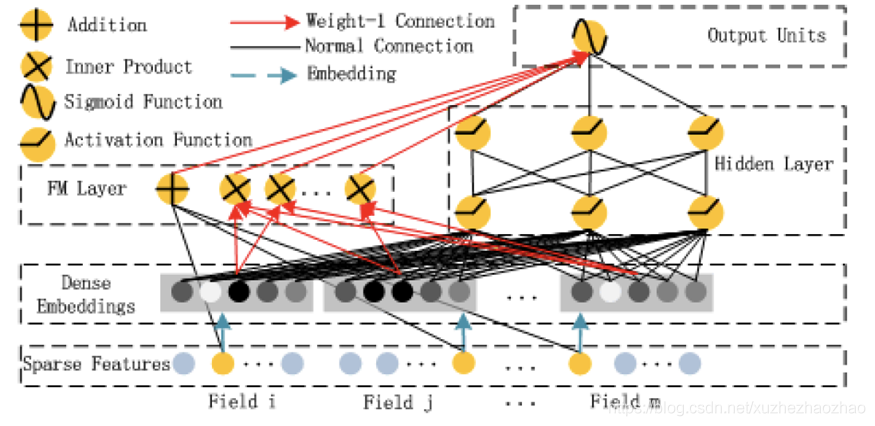
DeepFM
wide & deep 模型中,wide 部分仍然需要人工交叉特征。所以,很自然的,将 wide&deep 中的
wide部分替换成FM就好了。
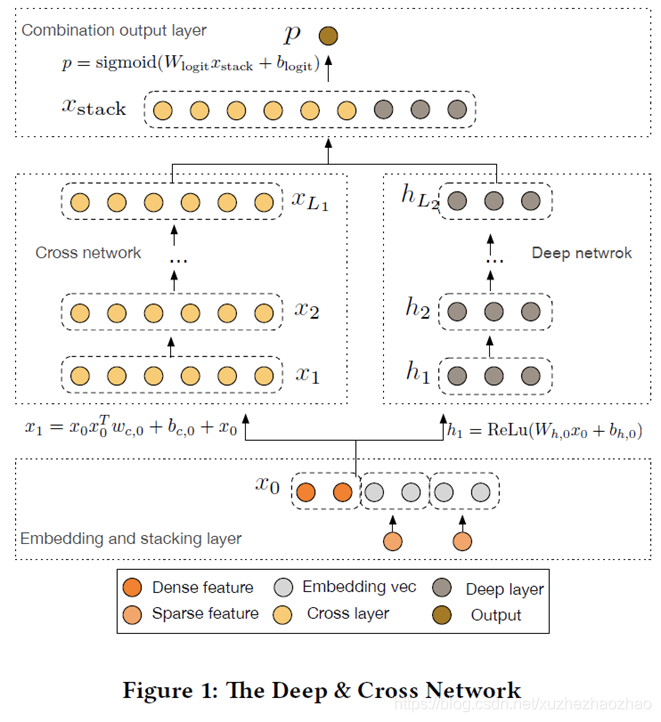
Deep&Cross(DCN)
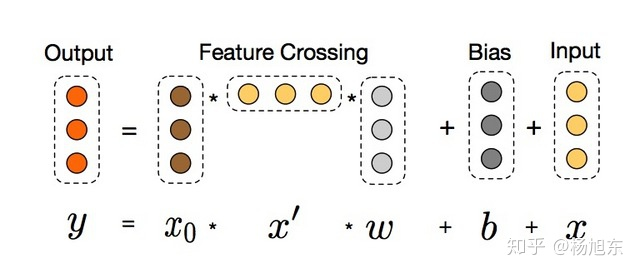
Deep&Wide模型 wide部分替换为Cross Network
Cross layer 的公式,借鉴了残差思想
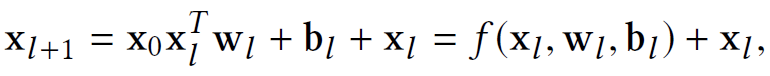
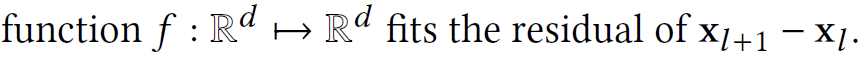
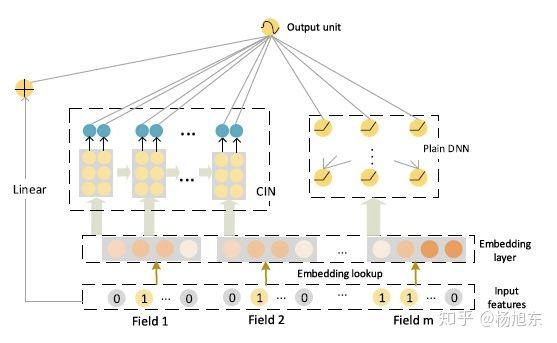
xDeepFM(CIN)
CIN 压缩交互网络(Compressed Interaction Network,简称CIN)
有了基础结构CIN之后,借鉴Wide&Deep和DeepFM等模型的设计,将CIN与线性回归单元、全连接神经网络单元组合在一起,得到最终的模型并命名为极深因子分解机xDeepFM
集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。
为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据;不同的模块也可以接入各自不同的输入数据,例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入一部分稀疏的特征子集。
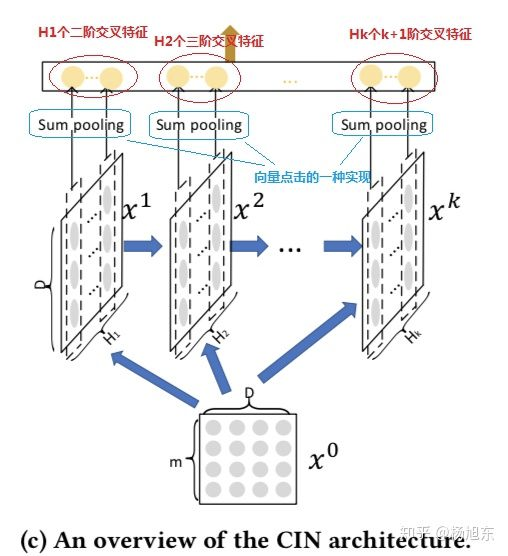
CIN的输入是所有field的embedding向量构成的矩阵 X^0 \in R^{m \times D} ,该矩阵的第 i 行对应第i个field的embedding向量,假设共有 m 个field,每个field的embedding向量的维度为 D
CIN中第 k 层的输出 X^k 由第 k-1 层的输出 X^{k-1} 和输入 X^0经过一个比较复杂的运算得到,具体地,矩阵X^k中的第 h 行的计算公式如下:
X_{h,}^k = \sum_{i=1}^{H_{k-1}}\sum_{j=1}^m{W_{ij}^{k,h}(X_{i,}^{k-1} \circ X_{j,*}^0)}
其中,\circ 表示哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量
\langle a_1,a_2,a_3 \rangle \circ \langle b_1,b_2,b_3\rangle =\langle a_1b_1,a_2b_2,a_3b_3 \rangle
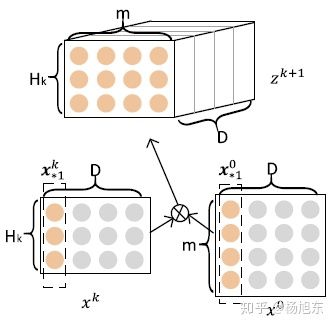
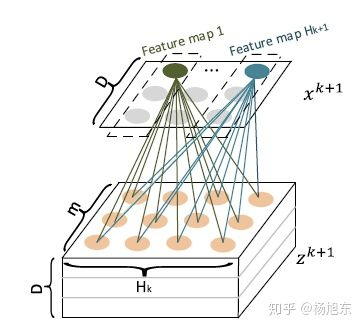
在计算 X^{k+1}时,定义一个中间变量 Z^{k+1} \in R^{H_k \times m \times D} , Z^{k+1}是一个数据立方体,由D个数据矩阵堆叠而成,其中每个数据矩阵是由X^k的一个列向量与X^0的一个列向量的外积运算(Outer product)而得,如图3所示。 Z^{k+1} 的生成过程实际上是由X^k与X^0沿着各自embedding向量的方向计算外积的过程。
Z^{k+1}可以被看作是一个宽度为 m 、高度为 H_k 、通道数为 D 的图像,在这个虚拟的图像上施加一些卷积操作即得到 X^{k+1} 。 W^{k,h} 是其中一个卷积核,总共有 H_{k+1}个不同的卷积核,因而借用CNN网络中的概念, X^{k+1} 可以看作是由 H_{k+1}个feature map堆叠而成
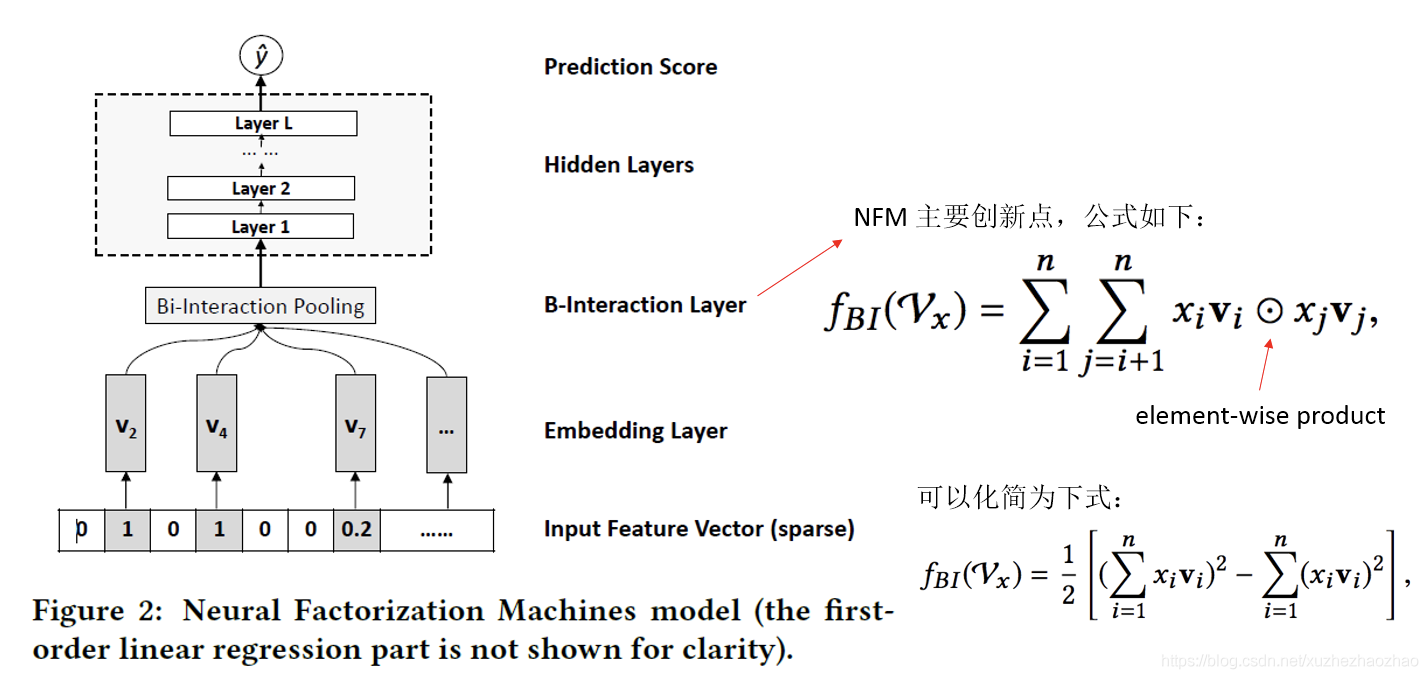
NFM
同样是 wide&deep 思路,不过改进的是 deep 部分
y(x) = w_0 + \sum^n_{i=1} w_ix_i + f(x)
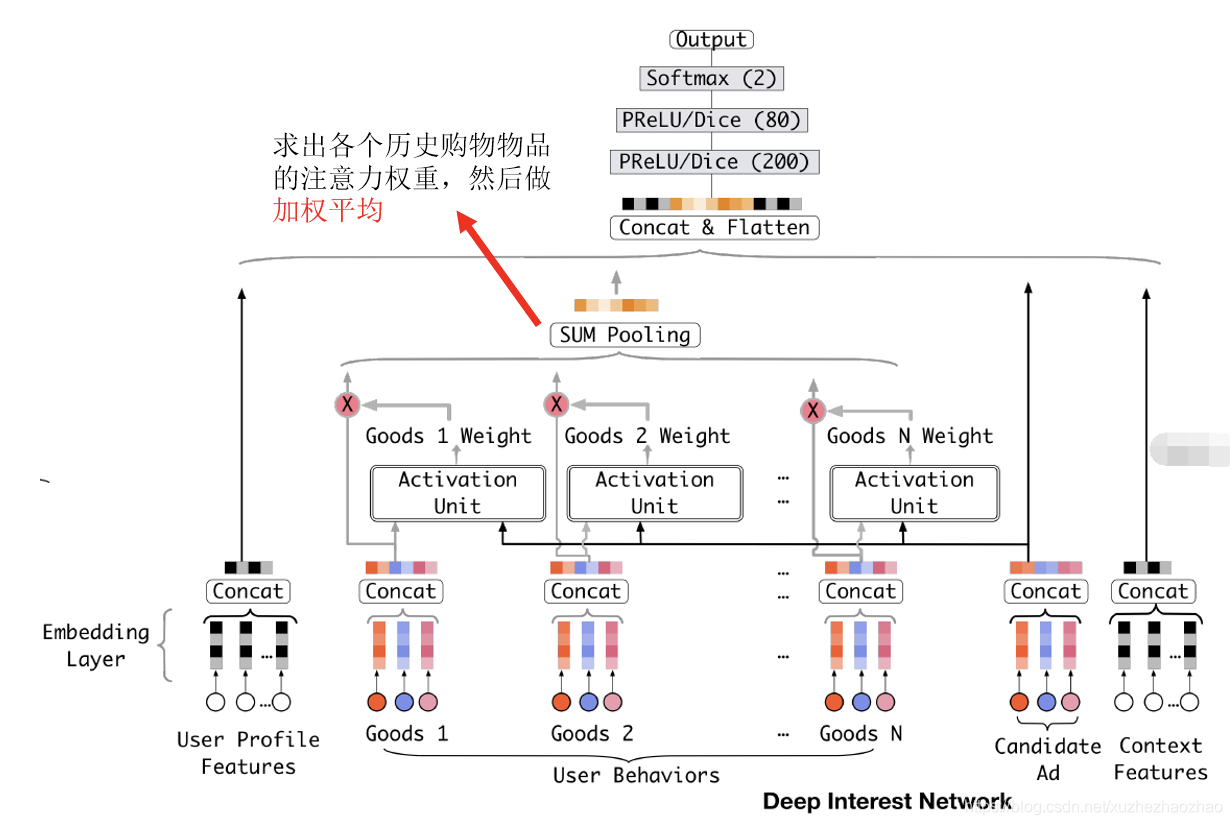
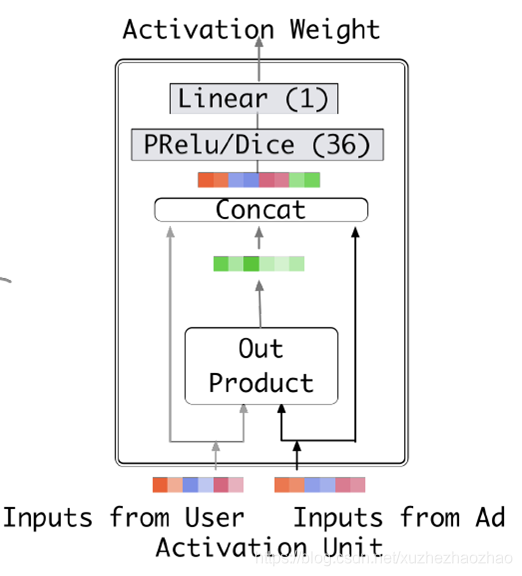
DIN
Deep Interest Network,来自阿里妈妈的精准定向检索及基础算法团队
DIN 原始的应用场景为淘宝购物,作者在实践中观察到用户的两个特点:
- Diversity:用户的购物兴趣是非常广泛的;
- Local Activation:一个爱游泳的人,他之前购买书籍、冰激凌、薯片、游泳镜。当前给他推荐的护目镜。那么他是否会点击这次广告,跟他之前是否购买过薯片、书籍、冰激凌一点关系也没有,而是与他之前购买过游泳帽有关系。也就是说在这一次 CTR 预估中,部分历史数据 (游泳镜) 起了决定作用,而其他的基本都没用。
如何来建模 Local Activation 这一行为呢?
答:引入起始于机器翻译中的 Attention 机制;核心思想:将待排序物品和单个历史购买物品输入进神经网络,神经网络的输出为单个数值,就是该历史购买物品的注意力权重。
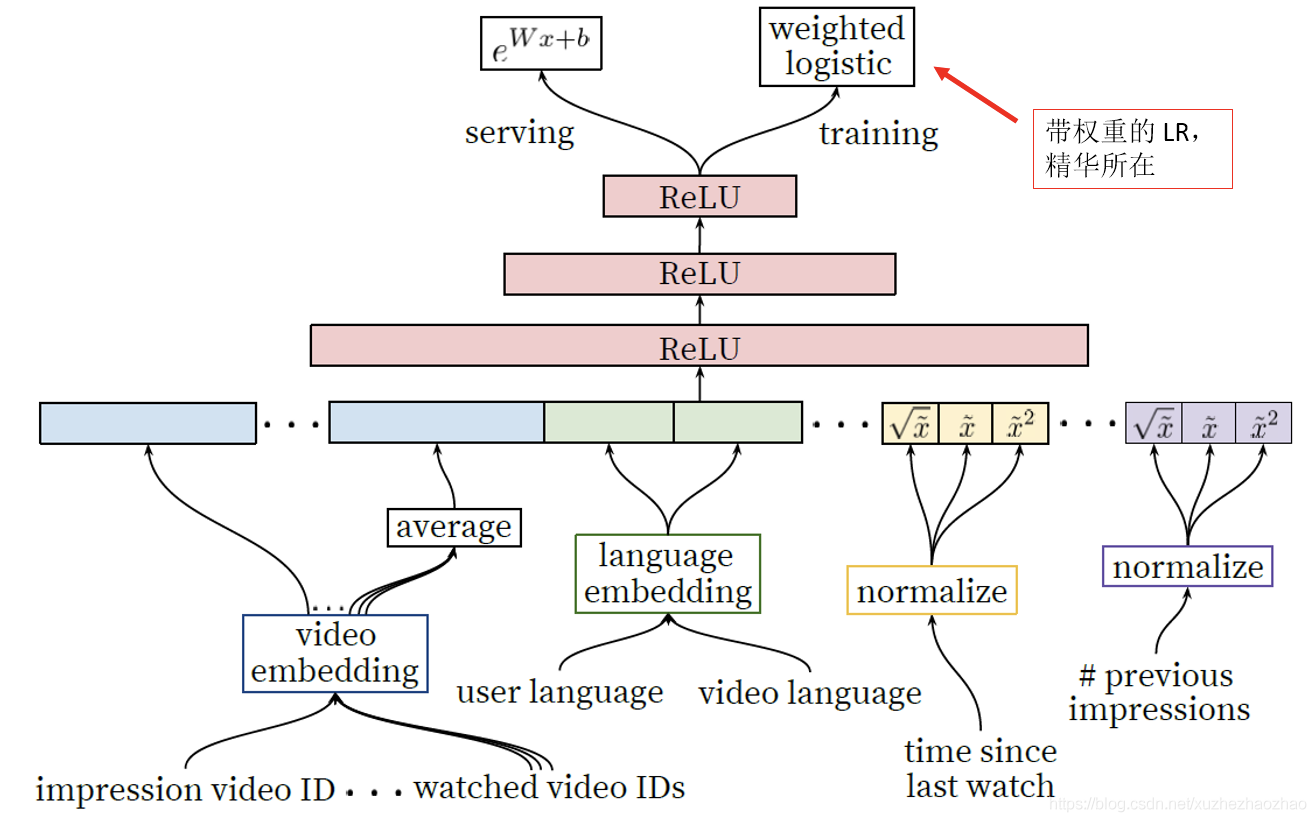
YouTube Deep Ranking
核心思想是:使用带权重的 LR,对于正样本,权重为用户观看时长,对于负样本,权重为 1,这样就将预测目标由 CTR 变为了预测用户观看该视频的期望时长。
其实就是普通的 deep 网络,只是最后使用了带权重的 LR loss。
FTRL
FTRL 实际上只是一个梯度更新算法,跟 SGD, Momentum, Adam 类似,不过一般是和 LR 一起用,因为通过 L1-正则化,它可以很好的产生稀疏化特征,非常适合超大规模 LR。
CTR 预估领域应用比较广的在线模型应该只有 FTRL LR 了