
AdaBoost是通过训练多个弱分类器(如决策树)根据其预测的准确度来决定其权值,最终使用这些分类器的投票来最终决定测试数据的类
对于每个分类器,他的准确率决定了他的权值: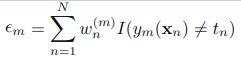
权值需要标准化: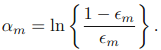
而每次训练分类器将会对训练数据的重要程度做改变,将之前分类错误的数据的权重提高,这样就能使之后的训练器更注重这部分数据从而提高总体准确度
对于每个数据的权值:![]()
标准化:![]()
最终通过所有分类器投票来得到最终结果:
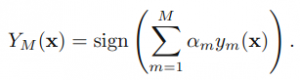
简单实现…没有使用矩阵运算:
import random
import numpy as np
class WeakClassifier:
def __init__(self, x_arr, y_arr):
self.x_arr = x_arr
self.y_arr = y_arr
def train(self):
return [random.randint(0, 10) for i in range(len(self.x_arr[0]))]
# Todo
# 添加训练代码
def pred(self, test_data):
return 1 if random.randint(-2, 1) > 0 else -1
# Todo
# 添加验证代码
# 正确输出 1 否则为 -1
class AdaBoost:
# method_class 为调用的弱分类器,包含train和pred方法
def __init__(self, x_arr, y_arr, method_class=WeakClassifier, m=5):
self.x_arr = x_arr
self.y_arr = y_arr
self.method = method_class
self.w = [float(1) / len(x_arr) for i in len(x_arr)]
self.classifier = [self.method(x_arr, y_arr) for i in range(m)]
self.c_ap = [0 for i in range(m)]
self.m = m
def train(self, iter=10):
# 训练每个弱分类器
for i in range(self.m):
self.classifier[i].train()
for iter_time in range(iter):
# 计算权值
for i in range(self.m):
# 获取分类结果
tmp_y = self.classifier[i].pred(self.y_arr)
# 计算加权误差
sum = 0
for j in range(len(self.y_arr)):
if tmp_y[j] == 1:
sum += self.w[j]
# 更新分类器话语权
self.c_ap[i] = 1 / 2 * np.log((1 - sum) / sum)
# 更新数据权值
sg = self.G[i].pred(self.X)
z = []
for j in range(len(self.y_arr)):
if tmp_y[j] == 1:
z.append(self.w[j] * np.exp(-self.c_ap[i]))
else:
z.append(self.w[j] * np.exp(self.c_ap[i]))
# 标准化权值并应用
tmp_x = []
for x in z:
tmp_x.append(x / sum(z))
self.w = tmp_x
def pred(self, test_set):
sums = 0
for i in range(self.m):
if self.classifier[i].pred(test_set) is 1:
sums += self.c_ap[i]
else:
sums -= self.c_ap[i]
# print sums
if sums >= 0:
return 1
else:
return -1