《Presto技术内幕》(1)
Presto Presto是专为大数据实时查询计算而设计开发的产品,拥有如下特点: – 多数据源:通过自定义Connector能支持Mysql,Hive,Kafka等多种数据源 – 支持SQL:完…

Simple And Naive
Presto Presto是专为大数据实时查询计算而设计开发的产品,拥有如下特点: – 多数据源:通过自定义Connector能支持Mysql,Hive,Kafka等多种数据源 – 支持SQL:完…
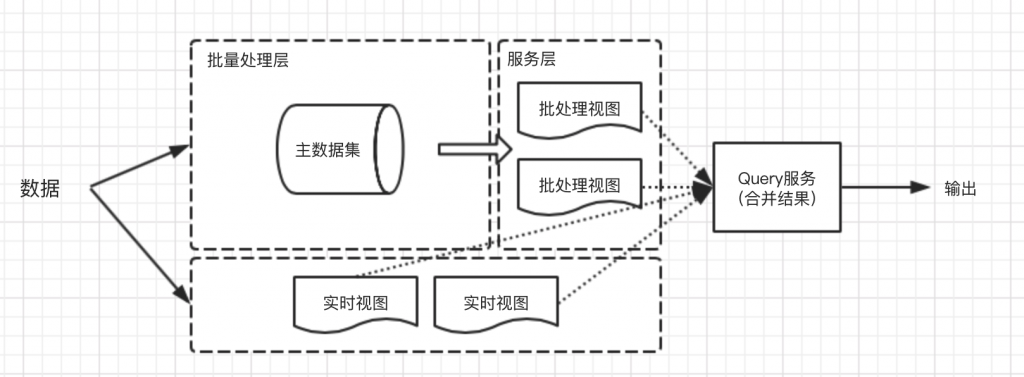
数据摄入 方式 流式数据:指不断产生数据的数据源,如消息队列,日志等;Druid提供了Push和Pull两种方式 Pull方式需要启动一个实时节点,通过不同的Firehose摄入 Push方式需要启动索引服务,提供一个H…

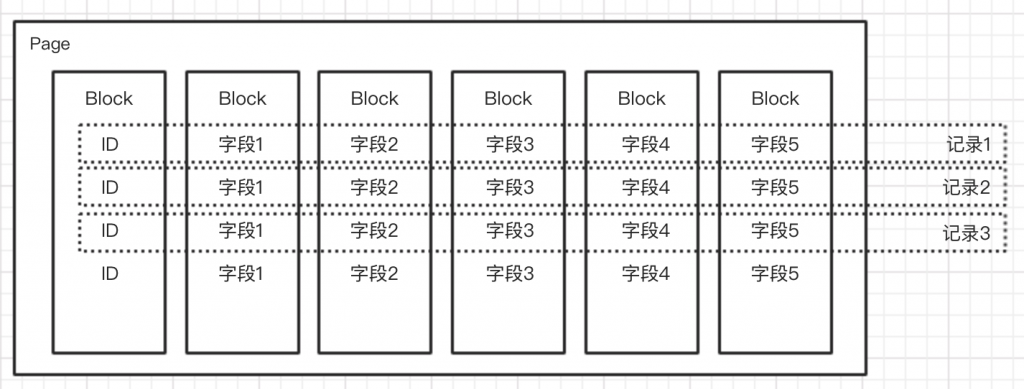
数据结构 DataSource(类似于表) 时间列:表明每行数据的时间,默认使用UTC并精确到毫秒 维度列:来自于OLAP概念,标识类别信息 指标列:用于聚合和计算的列,通常是一些数字 支持对任意指标列进行聚合(Roll…
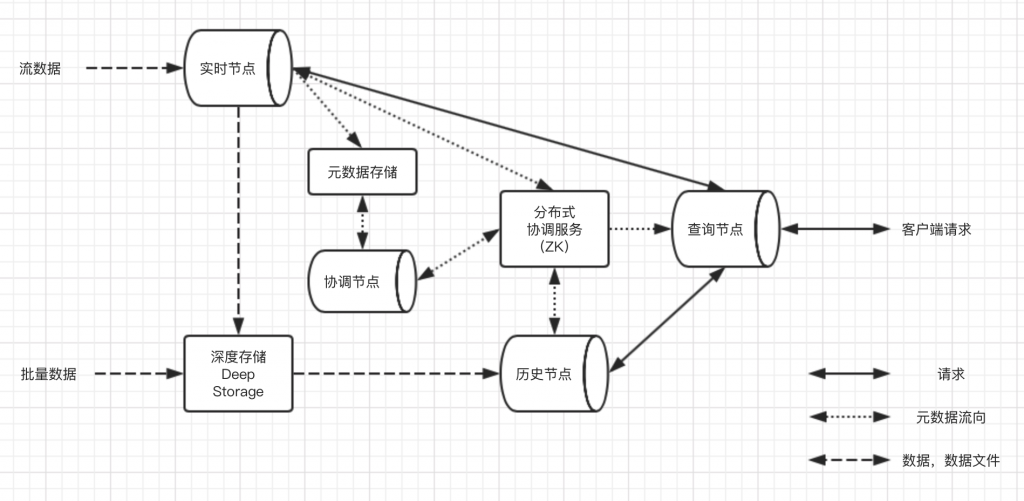
Druid Druid是一个分布式支持实时分析的数据存储系统,为分析而生,在处理数据的规模和数据处理实时性方面比传统OLAP系统有显著的性能改进。与阿里的druid无关 Druid的三个设计原则 快速查询:数据预聚合+内…
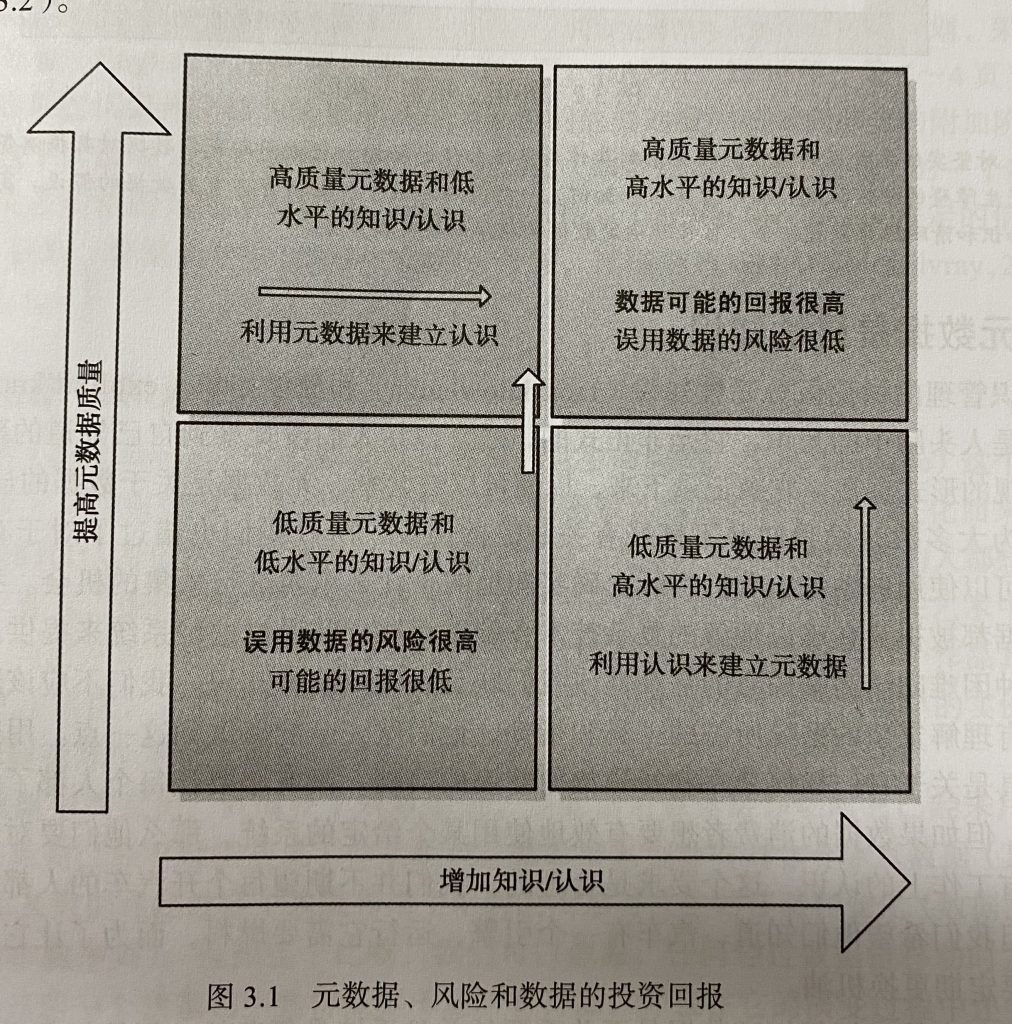
概念&定义 数据:在系统中以电子形式存储且共享的事实,可以是测量值,被编码的信息,或者对现实的描述 数据仅表示对象,事件和概念被选取的特征 数据是形式化的并具有上下文,其含义取决于他的构成方式 创建数据的过程是透…
SparkSQL 通过提供存放Row对象(一条记录)的SchemaRDD ,使用Spark+SQL来操作结构化和半结构化的数据,并支持透过JDBC、ODBC链接;支持与Py等代码融合。推荐使用HiveQL作为默认语言 在…
Mapper Skew Map端倾斜 输入文件分片尺寸差距太大 开启小文件合并 限制单Map最大最小输入 set mapred.max.split.size=32000000; set mapred.min.split.…