
《机器学习-周志华》笔记(五)
半监督学习 未标记样本 因为未标记样本与标记样本符合同一个模型生成(假设),因此希望学习器通过未标记样本来提高学习性能 生成式方法 假设所有数据由一个潜在模型生成,假设一种模型,通过极大似然估计求解(EM法) 通过当前模…

Simple And Naive
半监督学习 未标记样本 因为未标记样本与标记样本符合同一个模型生成(假设),因此希望学习器通过未标记样本来提高学习性能 生成式方法 假设所有数据由一个潜在模型生成,假设一种模型,通过极大似然估计求解(EM法) 通过当前模…
聚类 性能度量 or 有效性指标 两样本在同一个参考模型类中 两样本不在同一个参考模型中 两样本在同一个聚类类中 a=|SS| c=|DS| 两样本步子同一个聚类类中 b=|SD| d=|DD| avg(C) 样本间平均…
贝叶斯方法 贝叶斯决策论 基于概率和误判损失来选择最优标记 当属性是离散的: 类的先验概率 = 该类样本数量 / 样本总数 极大似然估计 通过极大似然估计得到的正态分布均值=样本均值,方差=(x-\\overline{u…
神经网络 包含隐层的网络即可称为多层神经网络 误差逆传播算法(BP) 对网络在数据集上的均方误差对各层权值做偏导,即可算出各个参数的梯度下降更新值 学习率控制了学习过程中每一轮迭代的更新步长 BP算法的目标是最小化训练级…
基本 奥卡姆剃刀原则 若有多个假设与观察一致,则选最简单的那个 “没有免费的午餐”定理(NoFreeLunch Theorem) 在所有问题出现机会相同时,所有算法期望性能相同 评估方法 留出法 将数据集划分为两个互斥的…
The spike-triggered average (STA) is a tool for characterizing the response properties of a neuron using the s…
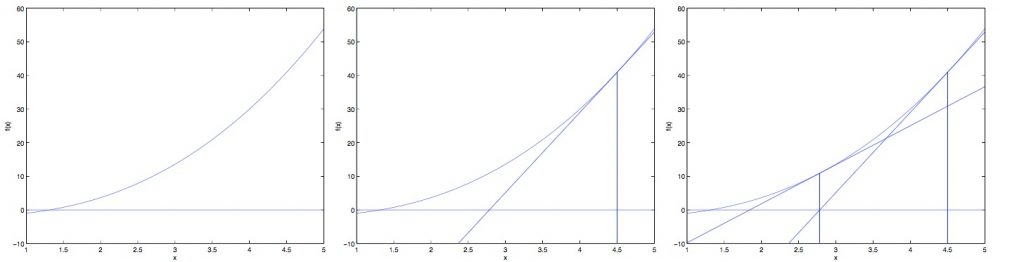
牛顿方法中,\\theta的调整方程为: 其中的意义为 函数在x点的切线与x轴的交点x值与x的差值 这样每一次迭代就可以让x值更接近于使时的x值。 可见在迭代过程中,每一个step的大小都不一样,是越来越小得这跟梯度下降…
逻辑回归一般用于处理不连续的二分分类问题。与线性回归不同,逻辑回归需要做出的预测往往是包含在[0,1]之间的,而一般的线性回归对于此类问题一般没有较好的表现。 在逻辑回归中,我们引入逻辑函数(logistic funct…
在线性回归中,用于衡量准确度的Cost函数为: 以下为该函数的推导过程: 在线性回归中我们认为任意数据集都可以通过一个线性函数来拟合: 其中最后一项与x本身无关,因此将作为一个参数矩阵,可以得到: 其中为误差项,即不在特…
首先我们有: 为矩阵的trace ,为矩阵对角线上(ii对)所有元素和 其中A为一个nxn的矩阵 trace有如下性质: 有如下性质: ——————…