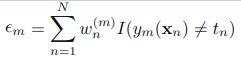
AdaBoost 算法 Python简单实现(未测试
AdaBoost是通过训练多个弱分类器(如决策树)根据其预测的准确度来决定其权值,最终使用这些分类器的投票来最终决定测试数据的类 对于每个分类器,他的准确率决定了他的权值: 权值需要标准化: 而每次训练分类器将会对训练数…

Simple And Naive
AdaBoost是通过训练多个弱分类器(如决策树)根据其预测的准确度来决定其权值,最终使用这些分类器的投票来最终决定测试数据的类 对于每个分类器,他的准确率决定了他的权值: 权值需要标准化: 而每次训练分类器将会对训练数…
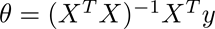
1、Normal Equation 标准矩阵 该方法一次计算即可得出结果。但是也可以多次处理。每次计算取样本数 = 样本特征数 + 1 公式为: 其中 X为训练样本。可见在训练前在每个样本属性前+1 Y为目标结果 Tha…
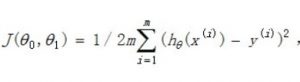
一般对于连续的值进行预测,使用回归的方式。 回归分为线性回归和逻辑回归,这里介绍比较简单的线性回归。 线性回归认为有一个函数 h(x) = ti*xi+b (其中xi为一个数据的第i个特征)可以使所有数据均围绕这个函数曲…

LDA降维即线性辨别分析,一般情况下都是吧数据降维至1-(C-1)维 其中C为总类别数,LDA降维的目标维度不可控 计算过程: 计算类内散度,散度矩阵是m∗m的对称矩阵,m是特征个数 首先计算类内均值 ,对每一类中的每条…
PCA降维,即主成分分析 主要过程为:先将数据标准化,然后求协方差矩阵,接着对协方差矩阵求特征向量和特征值,这些特征向量组成了新的特征空间。 标准化的方法一般有: min-max 均值 o-score 通过方差和均值来进…
实在没找到当条件子树的数据类似[[‘A’],[‘A’],[‘B’],[‘A’,’B’],[̵…
Apriori algorithm是关联规则里一项基本算法。是由Rakesh Agrawal和Ramakrishnan Srikant两位博士在1994年提出的关联规则挖掘算法。关联规则的目的就是在一个数据集中找出项与项…
C4.5 在 ID3的基础上使用信息增益率代替信息增益,减少了信息数量对优先级的影响 gain_rate(X,A) = gain(X,A) / split_in_word(A) 其中split_in_word是分裂信息度…
造轮子上瘾ing 果然只有自己从0撸算法才会理解的比较透彻 ID3决策树是基于信息增益和贪心法来递归建树 对于每一个节点选取信息增益最大的属性进行划分,当某个子数据集中仅存在一种分类时,则将其作为一个叶子节点 信息增益 …
写KD树的时候没把类别考虑进去。。。所以先用KD算出最近的k个点,然后找到对应分类最后输出占比最大的 KD树是一种二叉树,用来分割空间上得点 一个树节点的结构如下: class TreeNode: index = -1 …