《维度建模权威指南》(1)
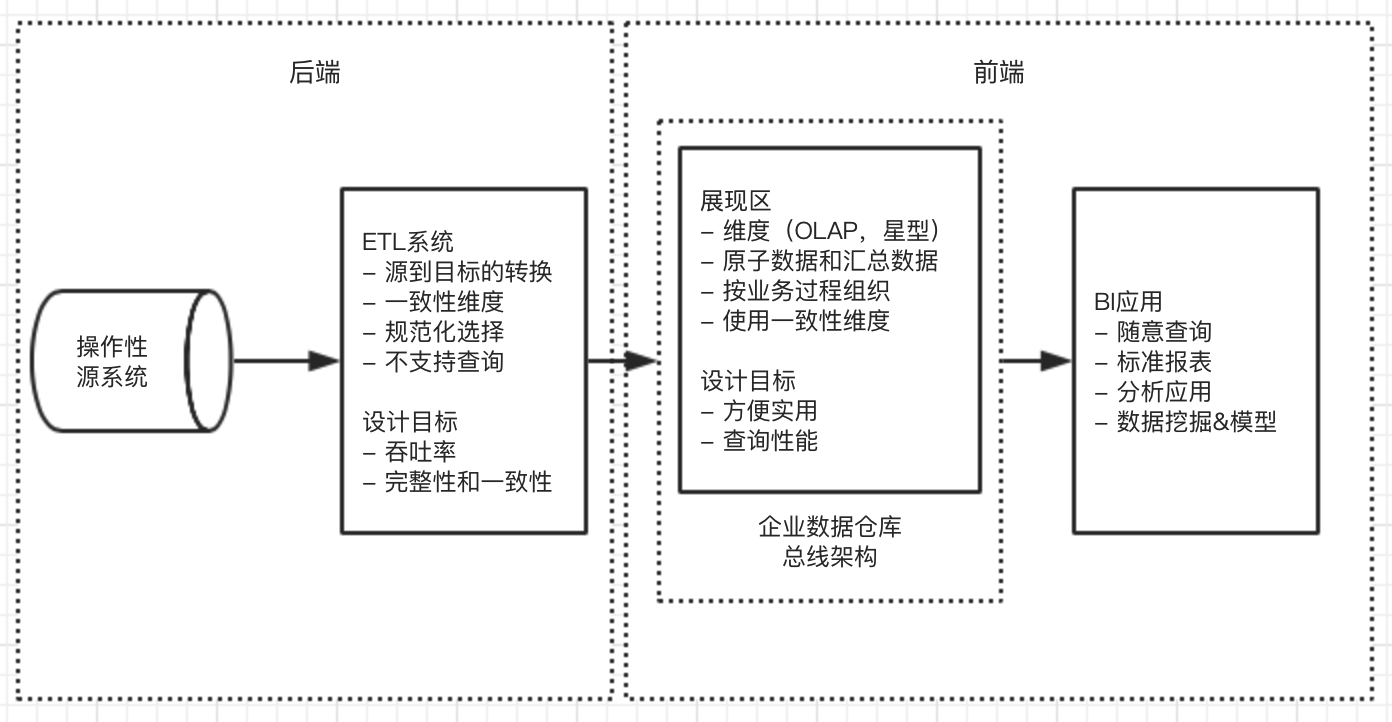
DW、BI维度建模初步 DW和BI的目标 系统要能方便的存取信息 简单、快捷 系统必须以一致的形式展现信息 数据可信,拥有一致的公共标识和定义,度量名称独立性 系统必须能适应变化 当业务问题发生变化或有新数据添加时,必须…

Simple And Naive
DW、BI维度建模初步 DW和BI的目标 系统要能方便的存取信息 简单、快捷 系统必须以一致的形式展现信息 数据可信,拥有一致的公共标识和定义,度量名称独立性 系统必须能适应变化 当业务问题发生变化或有新数据添加时,必须…

这次的需求是解析一个用表格布局的word的文件内的信息;word模板采用了两层表格的样式,因此采用python-docx包来进行解析,打算先把表格的内容按行列先读取出来。最早版本的代码如下: def table_nest…

Spark 运行时架构 一个节点负责中央调度,即驱动器节点,其他节点称为执行器节点。驱动器节点和执行器节点一起被称为一个Spark应用 驱动器节点 驱动器是执行驱动程序中main()方法的进程,执行用户编写的代码。他的职…
累加器 提供将工作节点中的值聚合到驱动器城区的语法。累加器的常见用途是调试时对时间进行技术。累加器用法如下: – 调用SparkContext.accumulator(initialValue)创造一个初始值…
键值对 Spark为键值对RDD提供一些转有方法如join(),reduceByKey()等。因此需要将数据转换成为键值对RDD才能应用上述方法。 创建 部分数据格式在读取时会直接返回为键值对,否则使用map()函数传入…
Spark 分析导论 Spark 软件栈 Spark Core 实现基本功能: – 任务调度 – 内存管理 – 错误恢复 – 存储交互 – 对 弹性分布式数据集…
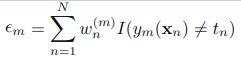
AdaBoost是通过训练多个弱分类器(如决策树)根据其预测的准确度来决定其权值,最终使用这些分类器的投票来最终决定测试数据的类 对于每个分类器,他的准确率决定了他的权值: 权值需要标准化: 而每次训练分类器将会对训练数…
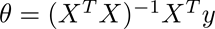
1、Normal Equation 标准矩阵 该方法一次计算即可得出结果。但是也可以多次处理。每次计算取样本数 = 样本特征数 + 1 公式为: 其中 X为训练样本。可见在训练前在每个样本属性前+1 Y为目标结果 Tha…
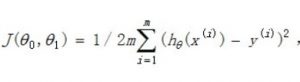
一般对于连续的值进行预测,使用回归的方式。 回归分为线性回归和逻辑回归,这里介绍比较简单的线性回归。 线性回归认为有一个函数 h(x) = ti*xi+b (其中xi为一个数据的第i个特征)可以使所有数据均围绕这个函数曲…
LDA降维即线性辨别分析,一般情况下都是吧数据降维至1-(C-1)维 其中C为总类别数,LDA降维的目标维度不可控 计算过程: 计算类内散度,散度矩阵是m∗m的对称矩阵,m是特征个数 首先计算类内均值 ,对每一类中的每条…